This is what Bob Stuart wrote:
Convention Paper 9178
Presented at the 137th Convention
2014 October 9–12 Los Angeles, USA
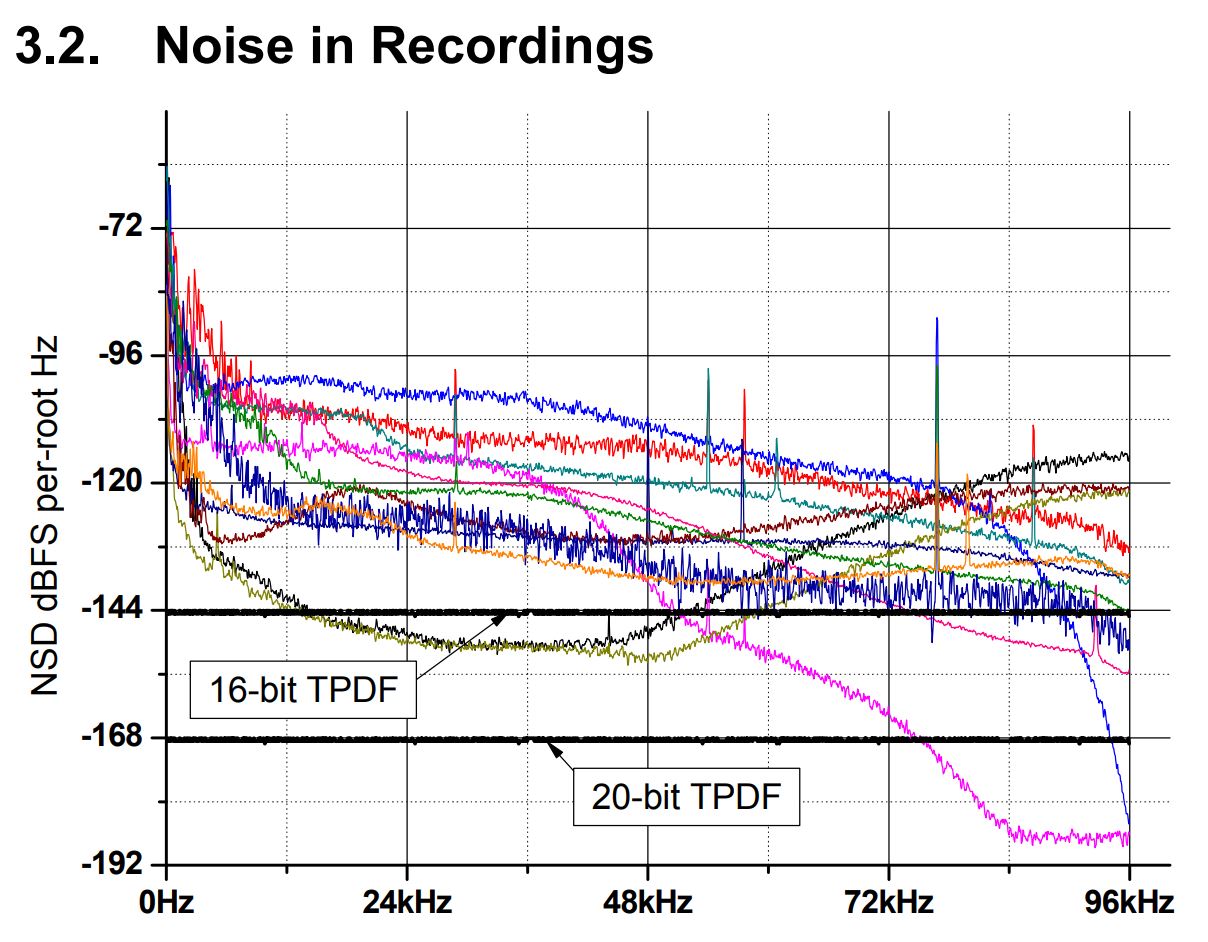
Figure 8. Examples of background noise in 192 kHz 24-
bit commercial releases. Also shown is TPDF dither
noise for 192-kHz 16- and 20-bit quantization. Curves
plotted as noise-spectral-density in 1-Hz bandwidth.
Above we see measurements of noise in recordings,
chosen to range from reissues from 60-year-old
unprocessed analogue tape to modern digital recordings.
Obviously these analyses embody the microphone and
room noise of the original venue, but in some, analogue
tape-recorder noise. Even the best recorder’s noise floor
is above that of an ideal 16-bit channel.
It is worth noticing that a 20-bit PCM channel is more
than adequate to contain these recordings and that
consequently 32-bit precision offers no clear benefit.
3.3. Environment and Microphones
Fellgett derived the fundamental limit for microphones,
based on detection of thermal noise, shown for an
omnidirectional microphone at 300°K in Figure 9 [52].
Cohen and Fielder included useful surveys of the selfnoise for several microphones [51]. Inherent noise is less
important if the microphone is close to the instrument and
mixing techniques are used, but for recordings made
from a normal listening position then the microphone is
a limiting factor on dynamic range – more so if several
microphones are mixed. Their data showed one
microphone with a noise-floor 5 dB below the human
hearing threshold, but other commonly used
microphones show mid-band noise 10 dB higher in level
than just-detectable noise. This further suggests that
those recordings can be entirely distributed in channels
using 18–20 bits.
3.4. Properties of Music
Content of interest to human listeners has temporal and
frequency structure and never fills a coding space
specified with independent ‘rectangular’ limits for
frequency and amplitude ranges. As we noted in Section
2.2, environmental sounds show a 1/f spectral tendency.
Ensembles of animal vocalizations and speech have selfsimilarity which leads to spectra that decline steadily
with frequency. Music is similar but the levels decline at
a progressively increasing rate
 ) is why the situation’s more ominous than just ditching Tidal for Qobuz.
) is why the situation’s more ominous than just ditching Tidal for Qobuz.