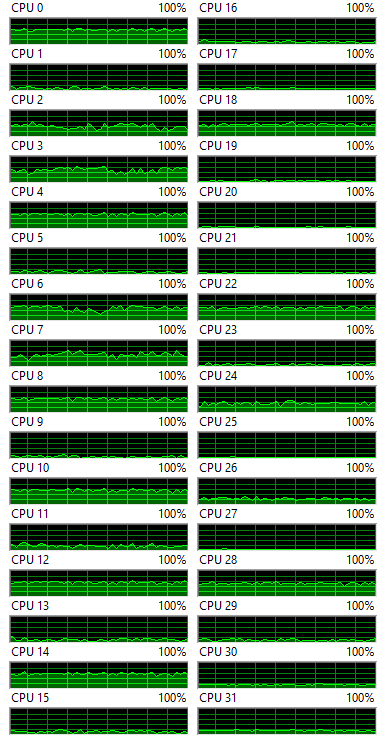
I am an experienced developer and have my own heavily threaded product. And for whatever reason, I started thinking about how to increase the parallelization in HQPlayer, since that’s one of its “less-strong” parts. And I think I have a working idea, even though @jussi_laako might have considered it and rejected it already. But just in case, here it is.
The idea is to divide the execution in many parts, where each part can be started as soon as the previous part is done and before any later parts are started. Very similar to how pipelining works for modern RISC CPUs, except there will be no guarantee that each part takes equally long. As many parts as possible should be identified and used, since each part will execute in its own thread/process and increase parallelization. And the more equal the parts is in execution time, the better.
Below is an example for how this could look for DSD up-sampling with convolution and some additional DSP.
Part A - Fetch for example 0.1 seconds of data from input stream and perform volume calculation
Part B - perform convolution on output from A
Part C - perform other DSP in output from B
Part D - Up-sample output from C to PCM
Part E - Convert output from D to DSD
Part F - Do modulator on output from E
Execution would then look like this
Thread/process 1: ABCDEF
Thread/process 2: -ABCDEF
Thread/process 3: --ABCDEF
Thread/process 4: ---ABCDEF
Thread/process 5: ----ABCDEF
Thread/process 6: -----ABCDEF
Thread/process 1: ------ABCDEF
and so on
Note that threads/processes can be kept alive to avoid overhead of starting and stopping them. Some synchronization will be needed between execution units, but nothing to advanced (lock + FIFO queue etc.).
Total latency should be the same as before, maybe a few ms extra for overhead, and sound output is ready to start playing as soon as thread 1 is done with its last task.
And this example is for one channel, so a stereo output could use 12 threads and multi-channel would use even more.
And as mentioned, its not unlikely that more parts can be identified and used, which would increase the parallelization (for example when up-sampling to non-integer). Maybe each *2 up-sampling could be its own part. And maybe internal parts can be identified in the modulator and/or PCM → DSD. If CUDA is used, CUDA execution will be its own part (which it probably already is).
Note that if correctly implemented, more parts than CPU cores available will have very little impact, but if needed execution can stall until a core is available (assume one thread or process for one core, even though the OS might switch them around).
The key in this example is probably the modulator and its likely that it needs to be divided into its own parts, especially the EC modulator, for this to work very well (it will still work, but won’t yield as good parallelization).