I support 3 files. Maybe one more for randomisation, but 10 is too much…
format 24/44.1 preferably something (semi)acoustic but not necessarily classical.
My suggestion is a track from WomanChild by Cecilie McLorin Salvant.
We are not looking for best sound - only if we can differentiate between NULL filtered tracks. May I suggest this:
We use 3 pieces music:
For each piece we are given 3 versions:
Original untouched version - disclosed to us
Unknown version - NULL filtered
Unknown version - same as original
We have to listen and state which of the unknown versions in random order is the same as the original. Or state if we cannot tell the difference. No point in guessing and hoping for the best. It should be obviously different or we should simply state we cannot tell.
Do it 3 times for the 3 different music tracks.
Tracks:
- Simple voice/guitar or piano
- Acoustical classical orchestra
- Pop with strong dynamics
Will that work?
The test protocol is important too - it should be to listen to captured sound leaving Roon towards the DAC right? The point is to see if NULL convolution filters through Roon is audible or not.
OK, makes sense to have 3 pieces of music. I’ll let people comment and propose samples until tonight and will post the “test kit” here tomorrow.
For convolution I plan to use this IR file. @brian can you confirm it’s good?
Unfortunately I lot of my test tracks are in Tidal - if you’re playing out from Roon, shouldn’t matter no?
I find this one particularly easy to hear the difference: Jess Glynne - "My Love (Acoustic)
Why would you need to know which is the original? Based on your listening experience thus far you should be able to pick it out undisclosed. There should be 3, none discernible by virtue of participants being told which is which:
- original
- null convolution
- original or null convolution
I will provide 3 versions of a given sample. I will not tell which one is convoluted or original.
I have Tidal HQ so no pb. I will disable MQA.
We have Cecile McLorin and Jess Lyne, happy to get a third proposal (classical or at least acoustic only instruments?)
Toybox, from:
I made a terrible mistake with the spectrum analysis, above :(. Edited my original post, be careful with that incorrect info. Noise was 20dB higher, than I showed… Cannot fully rule out its audibility
I hope to be able to comment on the testing protocol, in 8 hours or so. I do have a few doubts…
Sorry, can’t find it, I see a lot remixes but not the acoustic version. Do you have a TIDAL link?
Whoa, I don’t claim to have special super human listening abilities. I simply speak of my experience to date.
There is no should or should not be able to do anything. The purpose of the test is not to establish that I can hear -100db sounds! I can’t! Let’s not go there when we are doing so well.
The purpose of the test should be to record the test tracks in different ways out of Roon to see if one can hear the Null filter and hopefully identify which part of the data handling is causing this.
Perhaps we should discuss this in more detail as it’s the key to the issue.
We can talk more about what tracks and what format to present the tracks later.
I think you’ve misunderstood where I’m coming from. I didn’t mean to imply you have superhuman listening abilities, only that given you’ve found the null convolution to sound different there should be no need to point out which is which. Pointing it out would simply serve to reinforce any potential cognitive bias. 100% agree re the purpose of the test, what I’ve proposed doesn’t alter that in any way.
Something electronic would be a bonus for me personally but happy to listen to anything! Presumably genre of music shouldn’t matter - theres an audible difference or there isn’t?
Great to see you take ownership, @alec_eiffel! Saves me a lot of trouble :).
Unfortunately, I cannot dedicate a lot of time for this post today. But seeing that this topic is growing at bit TOO fast to my taste, I’d like to express a few doubts. Before it is too late :).
As we all can probably see already, it is VERY difficult to make a good testing protocol.
A protocol, that both every participant can agree with, and provides proper answers.
I’m missing the first and most important step in this process : Which exact question, do we need to be answered ? Or, if you like : what will be our hypothesis ?
I believe we should first focus on that; our hypothesis. Once that is clear, then the requirements to get to proper answers, can follow logically from that.
Without hypothesis, I’m sure your’ll get answers. But those are likely answers, to questions you never asked…
(for instance : we perhaps do NOT want to know if this can be heard, on average, or across a broad population. We do NOT want to know, wich sounds better. Etc…).
I haven’t given it too much thought yet. It could be something like this :
“In certain circumstances, some inviduals are capable of reliably detecting an audible difference between sound that is NOT, versus sound that IS processed through what we call a ‘NULL’ filter.”
Can this be either proven, or rejected ?
Then, a few requirements can follow logically from that. For instance :
- Only allow people to participate, if they are reasonably certain of hearing a difference.
People who hear no difference, will contaminate the results unnessecarily (including them would shift the results closer to a 50/50 average distribution).
Remember : we want to find out if there is a difference in a ‘golden ear, and golden system’ situation. - You need a probability value for the results of each individual. If not, than the answers have almost no statistical meaning. In other words : each individual should repeat each test, at least a few times.
Etc. Again, : have not given it too much thought yet. But I believe that our focus should first be, on ‘asking the right question’.
I see that both ABX tesing (@evand), and duo-trio testing (@Leong_Kin_Foong1) are suggested. I don’t mind; both serve this goal.
As of now, I have a few problems with the protocol. I don’t mind at all if you continue, as-is.
But I would not take responsibility, for its outcome… My main problems (there are small others), are:
- Your files are identifiable, when played. People have physical access to the files. People can do the same diffmaker analysis on them, as you have already shown.
In other words : it is possible to find out, which file is what.
I like to trust people. But I also know : if you leave room for cheating, then there will always be people that take that opportuniy.
Remember : one cheating person is enough, to wrongfully ‘prove’ my hypothesis ! - The fact that the files are identifyable (file name), also means : each user can do each test, only once. After all : why would he answer the exact same question differently, the next time ?
And that means : all statistical significance is lost… :(.
(Example : Say an indivual ‘guesses’ sample 1 and 2 correctly, and sample 3 incorrectly. Would that mean that he is sensitive for the change in sample 1 and 2 ?)
I believe that at least these two problems, need a solution. Without solving, the result will have (let’s say it nicely  ) very limited validity.
) very limited validity.
This was a long story to say : shouldn’t we take a step back, before we continue so fast ? Let’s first agree, on what we exactly need to know ?
I highly doubt that this question can be properly answered, using three identifiable WAVs (for a number of different track), played through a player that shows their identity as well (=Roon)…
1 Like
Hypothesis:
- Roon DSP has a flaw. Applying a null convolution filter leads to a slightly lower sound quality when applying processings that are in theory fully transparent like a NULL convolution filter.
Discussion:
- A few people have experienced this (including me). It’s not a night and day thing, but still very audible in A/B/A/B comparison, switching DSP on and off. Loss of dynamic and liveliness are reported.
- These people may be fooled by themselves, pretending in good faith that there is a difference, because of some sort of psychoacoustic bias.
- Still there are several concurring reports potentially supporting the hypothesis, from people numerous enough and serious enough. They don’t seem to have the symptoms of hifi forum trolls: poor syntax, absence of humility, technical jargon fired from the hip…
- A first experiment in the digital domain showed that the digital signal is not bitperfect after a Roon or HQPlayer NULL convolution, but the difference between the original and the processed file is very little (<-100dB) and, in principle, should not be audible. Still, people hear differences between a DSP NULL convolution processed and unprocessed file…
The question we want to answer in the experiment : is Roon DSP digital output after a NULL convolution filter lower in sound quality than the original ?
Test protocol summary:
- 3 song samples (30sec-1min)
- each sample comes in 3 versions A, B, C. At least one version is Roon output without DSP. At least one version is Roon output with DSP and NULL convolution. Nobody but me knows what A, B and C are really.
- This information will be in an encrypted file that everybody will get before, and I’ll provide the key at the end, in case some don’t trust me
- For each song, people rank A, B and C, if they can, and provide comments and details on their setup.
-
@Marco_de_Jonge if you are able with Diffmaker only to tell me which is which with certainty only by analysing the data, congrats! Bet is accepted
- A, B, C will not be A, B, C but random letters, all different between songs.
- All the above is of course not a 100% indisputable protocol. I nevertheless have faith in this forum’s honesty.
Thinking of the song selection : maybe it’s wise to avoid TIDAL, so that we are absolutely sure to listen to exactly the same material processed in different ways. I have Cecile McLorin but not the others mentioned here, help needed ! Maybe Rodrigo and Gabriela live in Japan, Stairway to Heaven?
Great quality post !
I (probably) misread. I thought you were suggesting a classic ABX test.
So three samples : A, B and an other X which must the same as either A or B (but nobody knows except you).
Sample A and Sample B are dynamically/randomly assigned to a button at every start of each test. Noboby knows what sample is under that button (except for the algoritm).
Participant chooses each time, if he thinks X represents A or B.
But ALL 3 are different in your case (and one is ‘a secret sauce’). In that case : you are right, I can not take that bet :).
However and but. I think it is good that you clearly described your hypothesis and questions.
It deviates quite far, from what I believe we need. And now, at least I know that.
You apparently what to find out, which sample sounds best (rated 1-2-3).
I just want to know, if they are perceived differently.
That may seem like a silly subtelty, but it isn’t. ‘Your’ outcome might be, that the NULL-processed version is the preferred one.
The fun question now is : would that mean that Roon is doing the right thing ? In my personal opinion : NO. Roon would in that case be altering the perceived sound, while they shouldn’t.
The other thing that I still have problems with :
Unless I misunderstand, each participant can only still do each test (=song), once. You don’t give different answers, when you are asked the same questions.
This means that you can only do statistical analysis, on the group as a whole.
You cannot zoom in to take a look at the individual level. N=1 gives no statistical value, at all. It does not mean anything, guessing or plain luck cannot be seperated from truthful answers.
Is that really what ‘we’ want to know ? Whether the average of the group hears ‘something’ ? Group results are typically overshadowing the results, of the ‘special’ individuals within that group…
Please do say if I misunderstood this last part. Is pretty important to know… :).
You do great work, by the way ! Hope that this isn’t understood as being overly critical. Just : the better our preparation, the better the information that comes out.
I would hate to see answers, that we don’t need.
It just occurred to me, that my objection can be explained much more easily.
I’m sorry if this is too obvious; I just do not know all of your backgrounds…
Effectively, you (@alec_eiffel) are asking participants to throw a 3-sided dice (=Sample A, B & C).
Throw that thing, 3 times (= state your series of preference. Possible outcomes : ABC, ACB, BAC, BCA, CAB, CBA).
Six possible outcomes. So : a chance of 1 in 6 to get it right. Even if there is nothing to detect at all in the samples.
If we have 6 or more participants, then we are reasonably sure that somebody will get it right. Right as in : according to your expectation or hypothesis.
Even when everybody was just guessing, or when the samples were tampered with in any way.
Concluding : We cannot use this test as stand-alone, it is just not reliable at all.
You then repeat the test with different test tracks; 3 in total. That is good : it improves the reliabilily.
(As long as we all accept, that we should be sensitive for this sonic change in ALL tracks).
For each individual , probability of picking all ‘right’ answers now is : one sixth, times one sixth, times one sixths.
Or : 1/216th, equating to ~ 0,46 %. Or : you need 200 participants, to be reasonably sure of a randomly chosen ‘right’ answer.
Although still not extremely convincing : That does seem a lot better, indeed.
But :do we all accept, that we should be sensitive to the change in ALL three sound tracks ?
If not, you must fall back to the first scenario. The one-in-six one, which certainly has no validity whatsoever…
(Please do know : I’m the worst statistician ever :). In fact, I avoid it when I can…)
(Yes, this was the reason why I originally stated : “I’m not sure if I’m willing to set this up”. It is very difficult perform this task well, while keeping your participants happy…  )
)
Finally, a question from my side : what will be the function, of using the the third ‘unknown’ sample ? I do not see a purpose for it, related to your hypothesis.
1 Like
This post is not about the organisation of tests but about my afternoon’s attempts to nail down the issue by the way of experimentation and measurements.
Spoiler alert: I believe i have something for @brian to work on…
I felt very frustrated because of my unconclusive previous measurements. This morning again, I listened to some HD tracks, switching between “no DSP” and “DSP will Null convolution”, and finding a small but quite obvious gap.
I was also reading @Marco_de_Jonge good comments and ultimately realised that I was so convinced there was an issue, that I actually didn’t want to put some effort in organising a test that will be disputed and inconclusive…
So, taking the word of Brian that it is a math problem… back to maths then.
I started by challenging the robustness of my test platform, playing the same files several times, and checking that the recordings were always the same in a given setup. I consequently decided to select the Apowersoft loopback CoreAudio driver, who delivered consistent results, Soundflower proving to be unstable and not entirely reliable at 96kHz.
So the test-platform consists of a single MacBookAir i3 2014, 8Gb running all other software:
- Roon MacOS App, so local Roon Server and Bridge (v1.5 363 )
- HQPLayer Desktop MacOS trial version
- Audacity MacOS 2.30 (latest) for recording and export of files
- Audio DiffMaker 3.22 under Parallels/Windows 10 on the same Mac
- REW 5,20 for spectrum visualisation
- Apowersoft Device configured in Roon as fixed volume, 32bits, 192kHz max, no MQA.
Roon DSP is opened, and Null384kMono filter loaded.
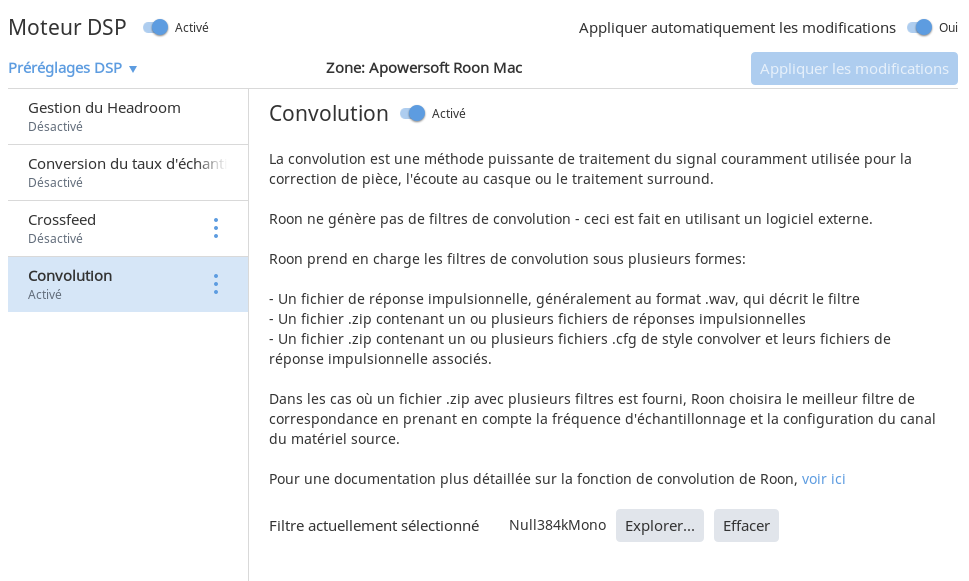
HQPlayer is configured without any resampling or dithering, see below for 44.1kHz test case:
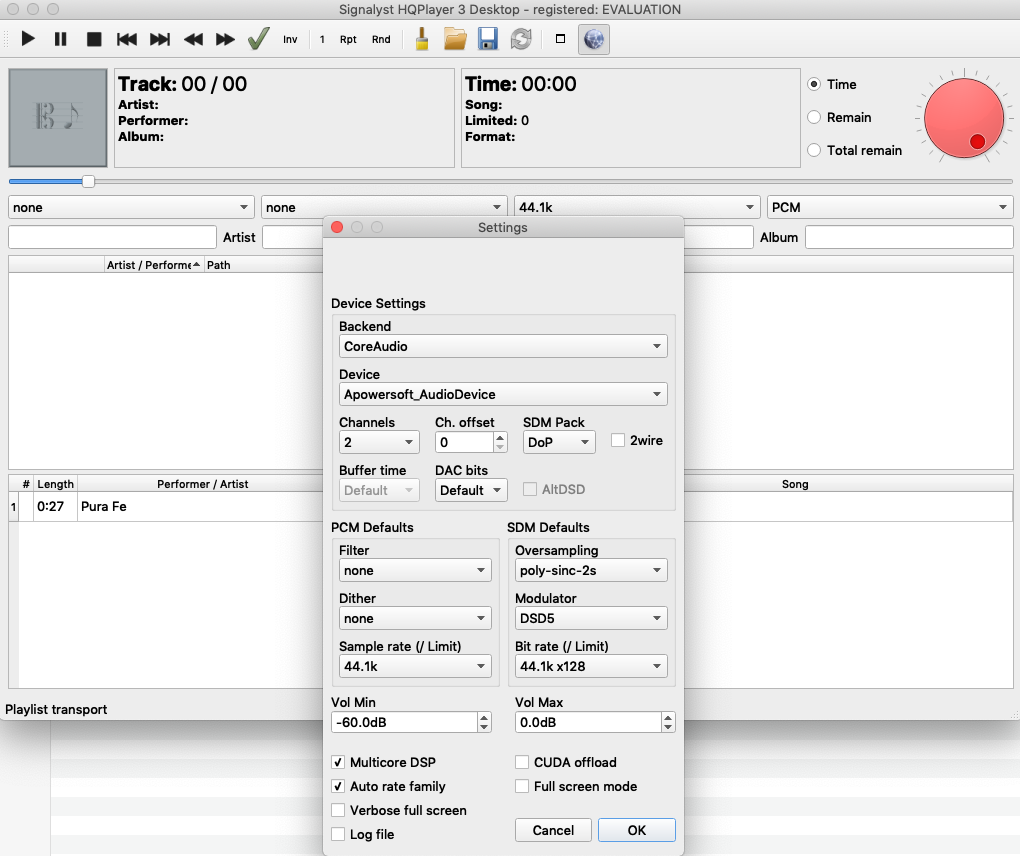
Convolution: DSP in HQPlayer is activated by ticking or not “enabled” on this screen
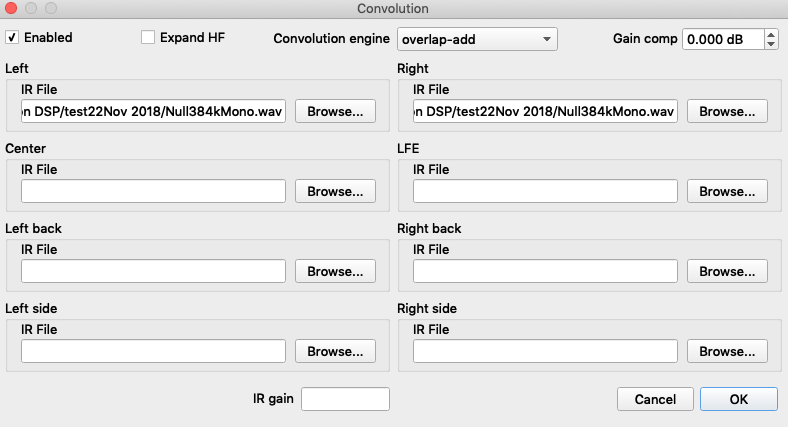
The same NullIR file is used in both Roon and HQPlayer.
CoreAudio device configuration is checked for gain and format, here for the 96kHz test case.
I then built with Audacity two “original” test samples of approx. 30 sec each:
- Cecile McLorin Salvant / I don’t know what time it was : 96kHz/24bit
- Pura Fe / Mohomoneh : 44.1kHz/16bit
The two files are stored in a local folder, in both HQplayer and Roon libraries.
Audio differences are computed with the oldie-but-goldie Audio DiffMaker utility:
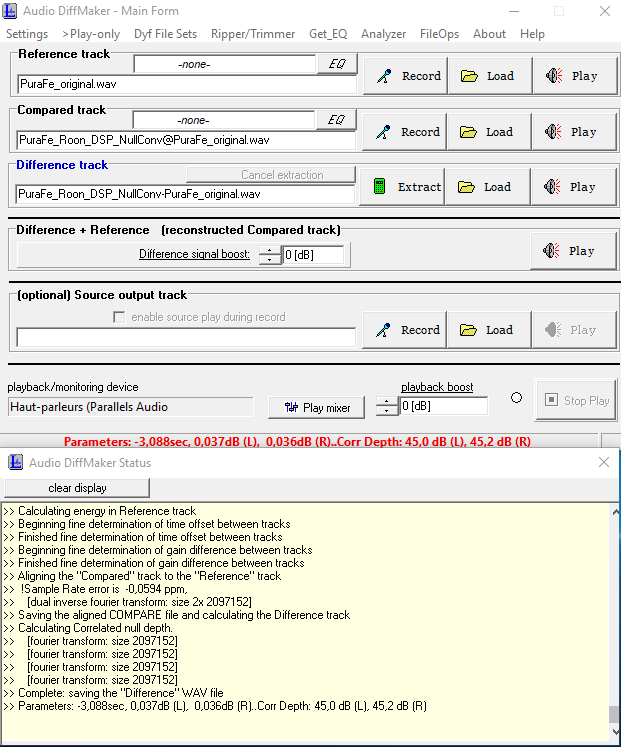
I started tests with sample “Cecile” 96/24. Results were, in comparison with the original:
-
Roon with no DSP --> bitperfect
-
Roon with DSP button activated but convolution disabled --> bitperfect
-
HQPlayer with no DSP --> bitperfect
-
HQPlayer with DSPNullConv on --> bitperfect!
-
Roon with DSPNullconv on --> not bitperfect, correlation depth of 93dB, quite poor for a 24bit file.
The difference with the original looks like this, magnified of 15dB.
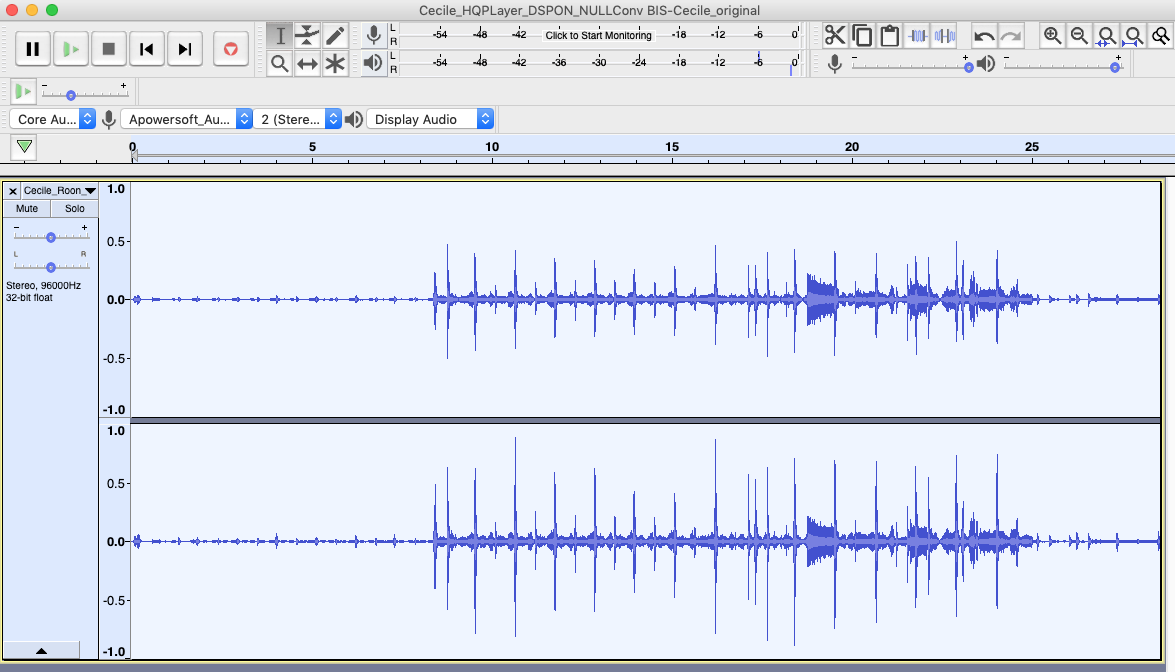
It’s mainly high frequencies, which means high frequencies are quite altered by the convolution. Definitely not looking like quantization/dithering noise.
I actually made the measurements for HQPLayer and Roon several times with the Null convolution filter in or off, to check I had made no mistake. And I had not.
Then I decided to run the same series of test for the 44.1k/16bit file "PuraFe"
-
Roon with no DSP --> bitperfect
-
Roon with DSP button activated but convolution disabled --> (not done)
-
HQPlayer with no DSP --> bitperfect
-
HQPlayer with DSPNullConv on --> not bitperfect
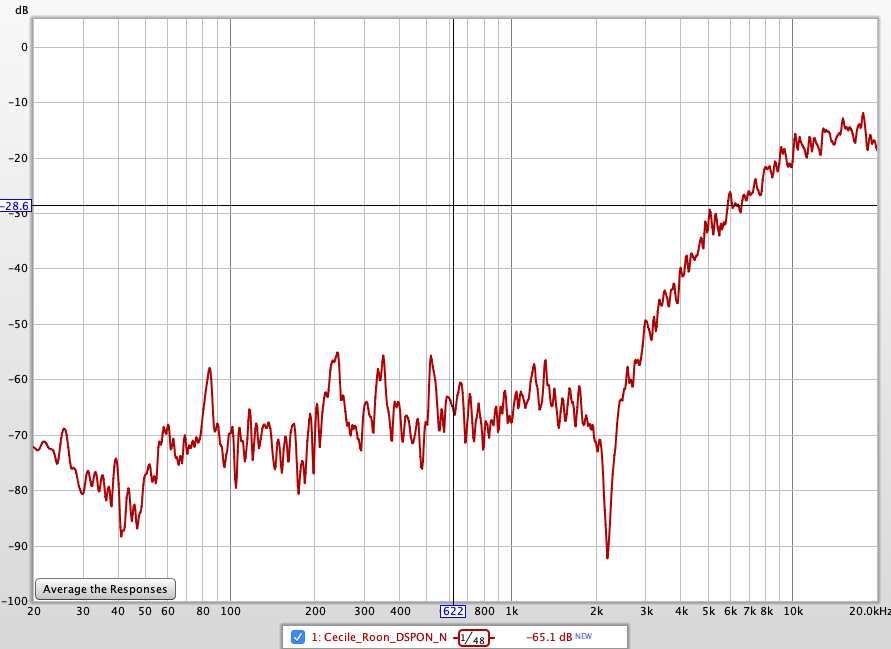
Correlation depth with HQPlayer was 85dB (about 14 bits). The difference file magnified of 75dB looks like:
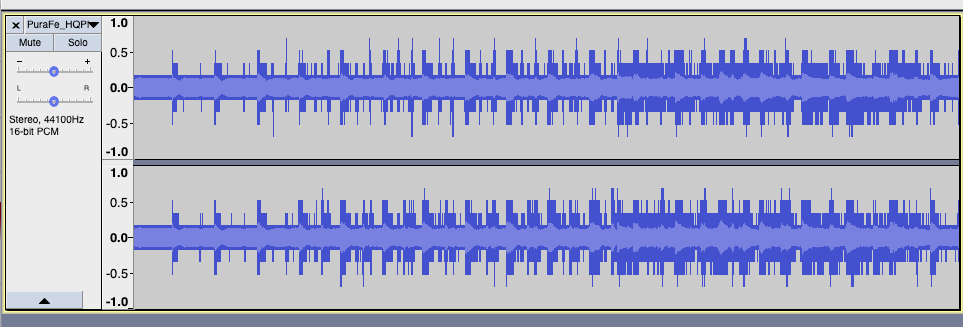
and its spectrum is:
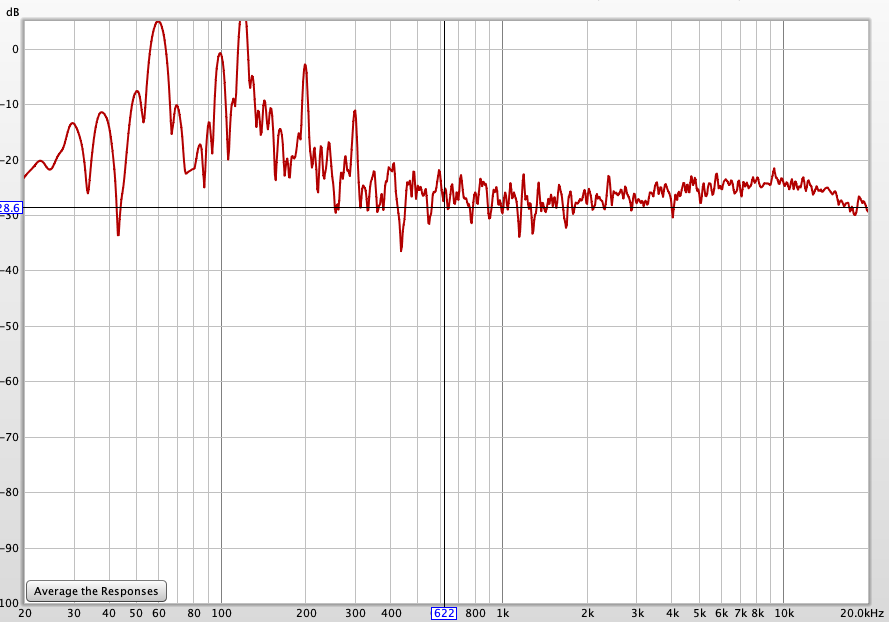
It’s reasonably small and could be dithering noise within HQPlayer or the CoreAudio engine (which is 32bits so there are conversions).
- Roon with DSPNullconv on --> NOT bitperfect at all , correlation depth of 45dB only! This is clearly way within audibility range.
Spectrum (in red) has strong HF content compared to HQPlayer case(in blue):
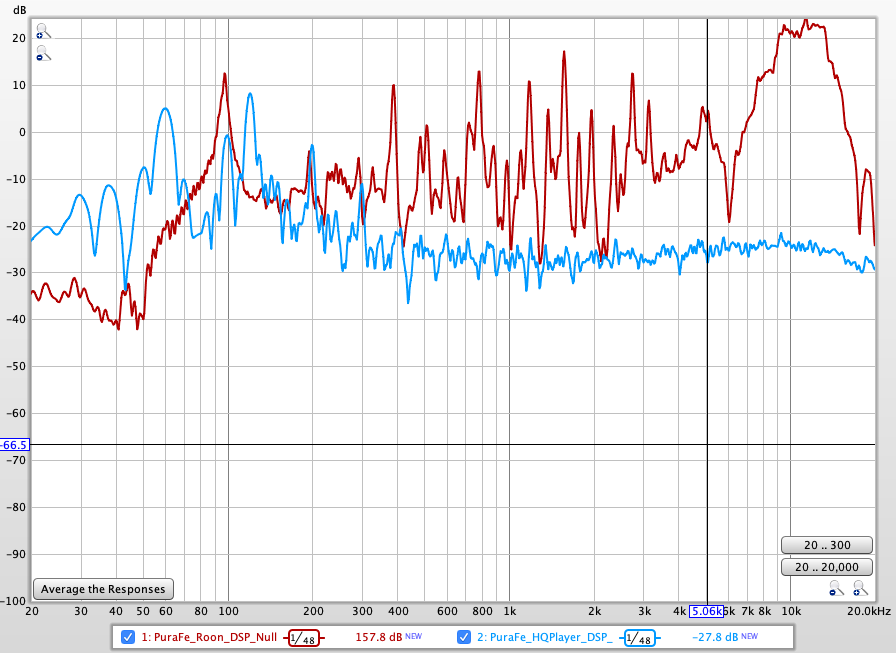
At this point I had evidenced that there really was an issue with Roon Convolution engine compared to the one of HQPlayer, which behaves as one would expect.
Then I really scratched my head hard. Yesterday, Roon has a better performance than HQ Player in terms of differences between orignal file and processed file… What the … ?
And, then this happened.

I got it. I knew what the issue was.
I double checked my settings of yesterday : I had a 96K Null IR in the Roon’s convolution engine, and I was playing a 96KHz sample. And Roon behaved well. But today, I had a 384k IR… In principle resampled by Roon automatically, as explained in the DSP online documentation.
Immediately I tried a 44.1k Null IR on my PuraFe sample and… bingo ! The correlation depth cae out as exactly the same as HQ PLayer. The spectrum was exactly the same, see HQPlayer in blue, Roon in mustard yellow,. I had to artificially offset the curves so that you see them, in practise they are exactly the same. Roon with 384k IR is in red.
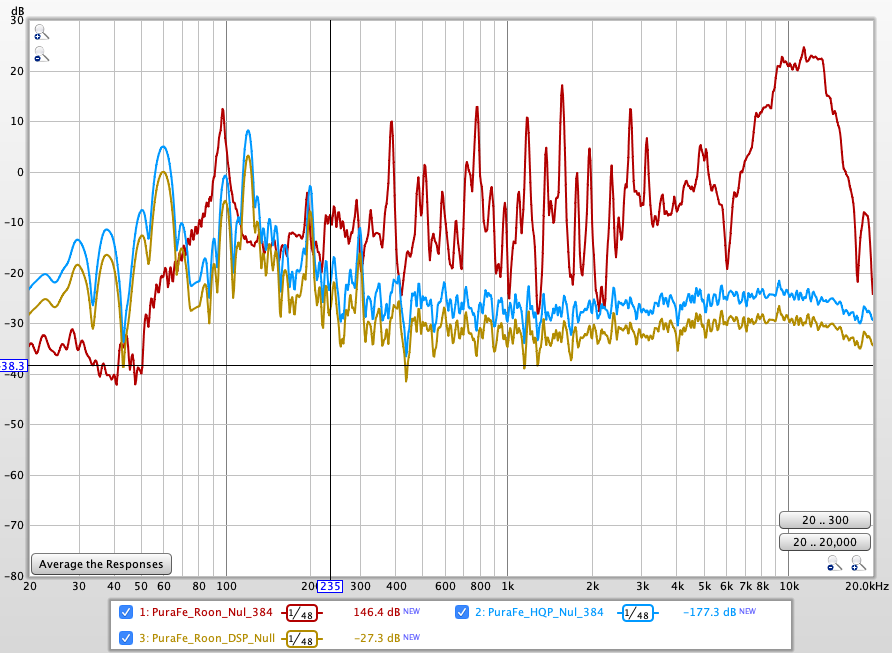
Back to the 96k “Cecile” sample. I uploaded a 96K Null IR in Roon and, bingo again:
-
correlation depth of 165dB, this is more than 70dB better than with the 384k IR !
-
still it doesn’t achieve bit perfect
Amplitude magnified of 120dB and spectrum of the difference file original/processed are:
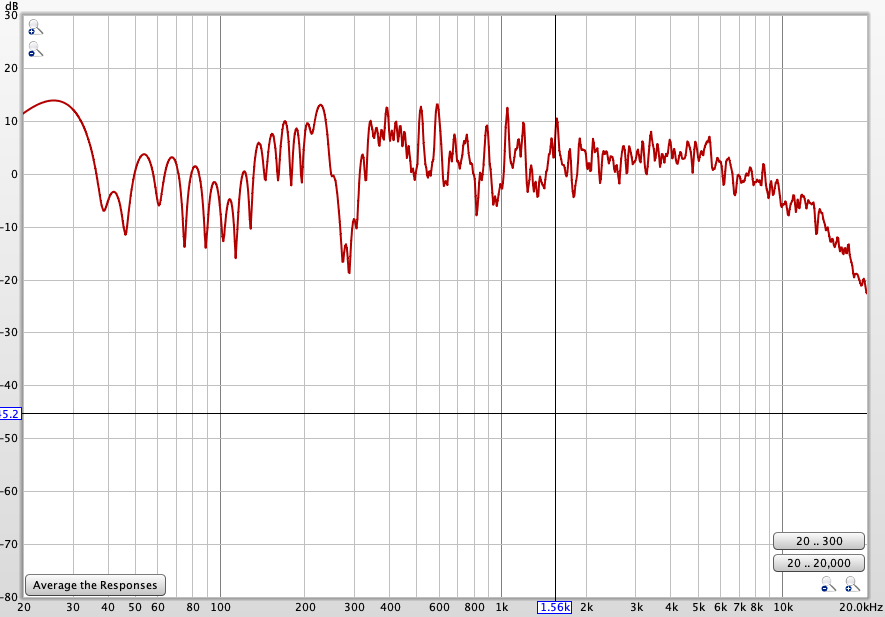
The offset in the magnitude is to be explained. The spectrum looks more like flat/quantization noise.
I have tested HQPlayer with the same 96k Null IR filter on the same file : the result is bitperfect, like with the 384k Null IR.
In conclusion, I am now convinced of two things, the first one at least requiring immediate attention from the Roon team/@brian:
-
There is a design issue / a bug in the impulse response resampling algorithm of Roon, that is provoking measurable and audible artefacts
-
A 96k Null convolution filter applied to a 96kHz/24bit stream is not bitperfect in Roon (even though it’s very close, correlation depth is >160dB). For the same IR and same file, HQPlayer is bitperfect. Mathematically and theorically, it should be bit perfect.
The only workaround I see for now is to make sure that the .zip file you are uploading comprises all possible sampling rates for your material. Roon then should automatically pick up the right IR, and not resample.
NB: my filters so far were 44.1kHz only, because I thought Roon would resample them correctly to 88kHz or 96Hz (I have a few 24/96 albums). I think I started to “feel” something different and having issues when MQA was launched by TIDAL and integrated in Roon : most of the 44.1kHz material is upsampled to 88.2kHz. My filters were good at 44.1kHz, but not at 88.2kHz due to the IR resampling bug.
NB 2: for those interested to cross-check my findings and dig deeper, all the original, recorded and Audio Diffmaker processed files are stored here. Titles are self-explicit. When no rate for NullConv is mentionned, 384k has been used. It would be good if someone could run comparable tests to consolidate my analysis.
7 Likes
There is a design issue / a bug in the impulse response resampling algorithm of Roon, that is provoking measurable and audible artefacts
Excellent analysis. I can absolutely believe that we have a bug with resampling IR’s that could have snuck through our process. I think you have narrowed this down considerably.
A 96k Null convolution filter applied to a 96kHz/24bit stream is not bitperfect in Roon (even though it’s very close, correlation depth is >160dB). For the same IR and same file, HQPlayer is bitperfect. Mathematically and theorically, it should be bit perfect.
I would not expect anything involving signal processing in Roon to be bit-perfect because of dither when truncating from the 64bit float intermediate representation. It’s interesting that HQPlayer is bit-perfect here, but the dither is “on purpose” and not showing concerning measurements.
1 Like
Incredible work 