LevelDB is what we chose. It is not SQL… no SQL library would come even close to performing here. SQL databases normally implement something like LevelDB internally for their indexes.
Lots of software uses LevelDB – Autodesk AutoCAD and Google Chrome come to mind.
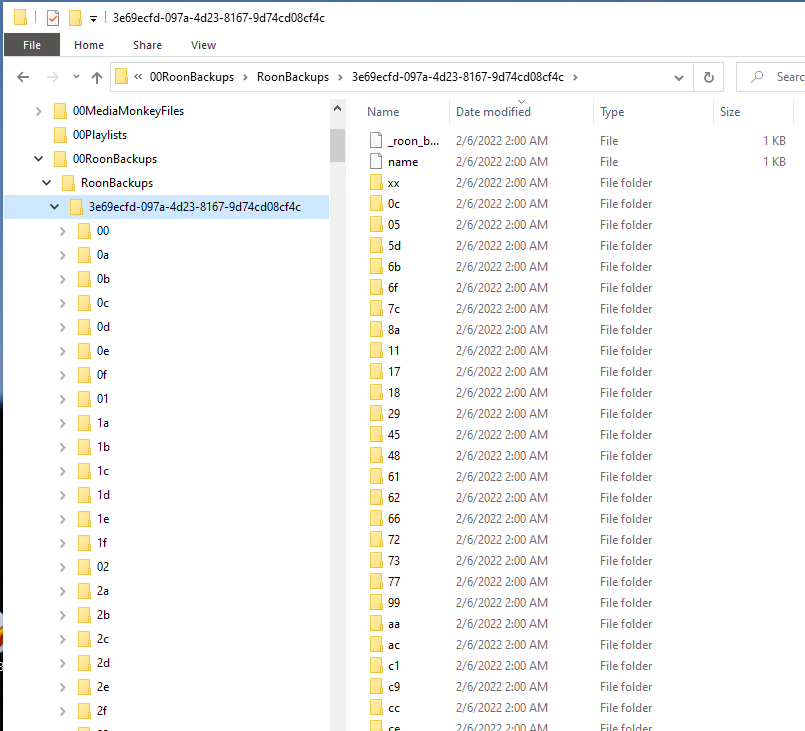
The other thing to note is that you have so many files because we save your artist photos and album artwork as individual files. We use a hashed deep directory structure to avoid having directories with many thousands of files, which can cause performance issues.
This is not an area we are changing, or even entertaining a change.
If your backup software is breaking, I suggest you use better software for your backups. If it’s just slow, well, that’s the reality of having all your data local.
Excuse me reviving a very old thread but, to add maybe a slightly different perspective, from my previous experiences with applications that store their databases as a few very big files that can be a total showstopper for anyone running incremental backup software. A tiny change such as correcting a single spelling mistake somewhere can result in the system updating maybe only a few bytes in one of its huge database files resulting in online backup software seeing a multi-GB file getting changed frequently and needing to be constantly backed up. If that’s a cloud backup service (e.g, Crashplan or Carbonite both of which I use) that can be so painful and impractical, especially given that domestic upload speed is usually lower than download speed, as to require such low granularity databases to be excluded from the cloud backups. (The Evernote note-taking app is a real life case of where I have had to very reluctantly exclude such a database from my cloud backups.)
In my opinion you’ve done exactly the right and most backup-friendly thing here Danny in terms of having high granularity in the database structure.
Good backup software will still send only the changes in a large file and do versioning. (For example, Synology’s HyperBackup stores backups as 32MB chunks and only the affected chunk(s) are updated. It then reference counts the assorted chunks, and keeps indexes to say which chunks are associated with which version so you can do point-in-time restores of older versions easily.)
Fair point but when choosing an online backup solution there are so many other key features that a user is often looking for and trying to balance all that against cost that it is still helpful for something like Roon to not introduce an additional feature requirement that a user has to accommodate. Because of that I’m grateful for Roon’s quite granular database.
Maybe I should go and check whether either of my current backup solutions (Crashplan & Carbonite) are smarter than I thought in large-file-backup. Certainly a few years ago when I first set things up I had an issue but I should file support tickets and recheck though so thanks for the info/insight.
As the live Roon DB is constantly being updated … the backup that is “snapshot” but the backup software may not be consistent … which can result in a corrupted DB when restored.
Thus, I would suggest:
Excluding the live Roon DB from the backup system.
Setting up Roon to perform a scheduled nightly backup (They are incremental and I have 99 days worth).
Include those backup folders in your overall cloud based backup system.
Seconded. I debated discussing this in my first reply, but they’d used examples like Evernote’s database being a problem for backups rather than Roon. With all databases, you really need to use the supplied backup tool to get a consistent export, and then you can back up that export with whatever your preferred backup tool is.
Roon makes it super easy to set up automatic backups of the metadata database as well, so no excuse not to. The backups don’t take up much additional space, either. In my case, I have Roon write the backups to a “Roon Backups” share on my NAS, and then the NAS’ backup software gets that up to AWS S3.
Noted. Thanks for the specific recommendation. Excluding the live DB and including automatically generated backups sounds like the way to go.
What is the format of the automatically created backups? Are they something like a big zip file to seed the process and then smaller incrementals on top of that or are they still quite granular as in the live DB?
I do realise that with Carl’s suggested scheme the initial seed (full) backup being a single very big file wouldn’t be a particular issue anyway since it would only be created once and it wouldn’t matter much if it took a day or two to make it up to cloud storage. Yes, in that case the seed would be out of sync with the increments for the first day or two as far as the cloud backups were concerned but that’s a transient issue. My question is motivated by curiosity and wish for a reasonably complete understanding rather than any concern about it being an issue.
The Roon Backup is not a single large zip file plus incremental files, (I sort of wish it was) it’s a complex folder structure with hundred of separate files within.
If you set it up and allow it to run (or force run it) check the overall file size and then check again after a few more backups have run you’ll see it doesn’t grow that much over and above the first cut.
I have Roon scheduled to perform a backup in the early hours of the morning each day with a max retention of 99 copies (I have the disk space so why not).
Thanks Carl & cwichura. That is extremely helpful and definitely gives me a good feel for the size of things.
So much to research, so many possibilities, so frustrating that my KEF LS50 wireless haven’t been delivered yet! Hopefully I can get an ETA on that on Monday and work out when it is sensible to start my Roon trial. I know that Roon is good about extending the 14 day trial but I don’t want to abuse that courtesy unnecessarily.
I thought 6 GB was a little big …but maybe it’s not. I should also be more clear. The 6 GB is my back up…I don’t know the actual DB size. Assume it’s similar.
I didn’t think Roon backups generally got larger than 2-3 GB but I guess I was wrong.
Hopefully backing up every day does not make the back up larger.
Windows PC Intel i7-10700K cpu 32 GB ram
Windows 10Pro 64bit 20H2 build 19042.1415
Connected Audio Devices
Auralic Vega G2.1 streamer DAC
Number of Tracks in Library
apox 15,000 mp3/flac files on roon core server + Qobuz
Description of Issue
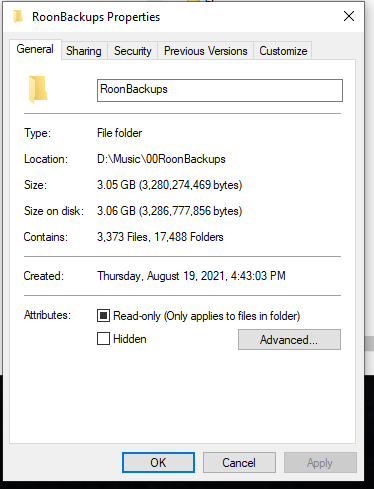
I have Roon backups set to run every 4 days and save a maximum of 10 backups. Backups are saved to a sub-folder on the server. This sub folder currently has 17,000 sub-folders and is 3GB large. What is going on here? No database backup should be this large and cumbersome.
Yeah, it’s not pretty and is using a hash of some kind to distribute the huge number of small files.
The size of the backup depends on the size of the DB to some degree but small files waste space. The block/cluster size on NTFS is still 4K if memory serves, effectively the minimum file size.
It’s worth putting the entire backup into a zip or compressed tar archive if you want to move/duplicate it…
That looks correct. Roon is not a relational database, but a key value one.
Requests have long been made to have the backup stored as a compressed zip file (or whatever compress of your choice), not so much to save space, but, to only have 1 file to then make a backup.
Whether relational or ISAM, databases like SQL or ESE store the database in one file. Using the filesystem as an index is not scalable (speaking from experience) and is also unnecessary since indexes need to be loaded in memory anyway. Serializing memory trees to a stream is easy, does not require any structured package and, IMH-dev-O, should have been done from the start.
Thanks everyone for the information. It’s a poor design, but now that I understand it I can work around it. I moved the backups to a different top-level directory so it doesn’t impede file searches for music and other useful items.