I think the discussion hasn’t really taken into account the two main aspects of digital storage.
tl;dr: data corruption is an issue that can occur on error-free and 100% healthy storage media.
Totally simplified, make sure to distinguish between:
-
The content (the user data, in this case your files of music in some format like FLAC perhaps)
-
The physical medium
a. the permanent storage (be it HDD, SSD, NVME etc.)
b. the active storage (RAM - in the form of DIMMs or SODIMMs etc.)
1 and 2 are completely different things.
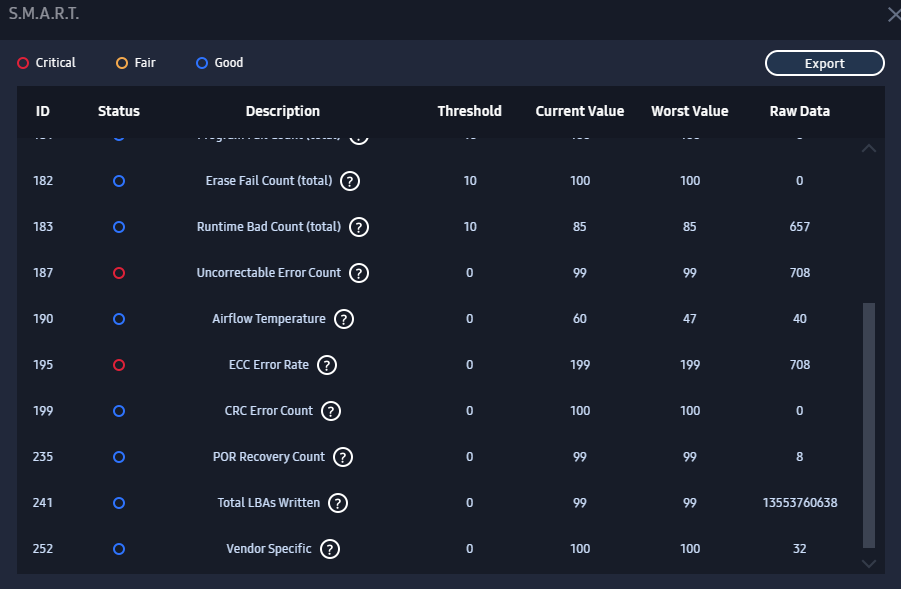
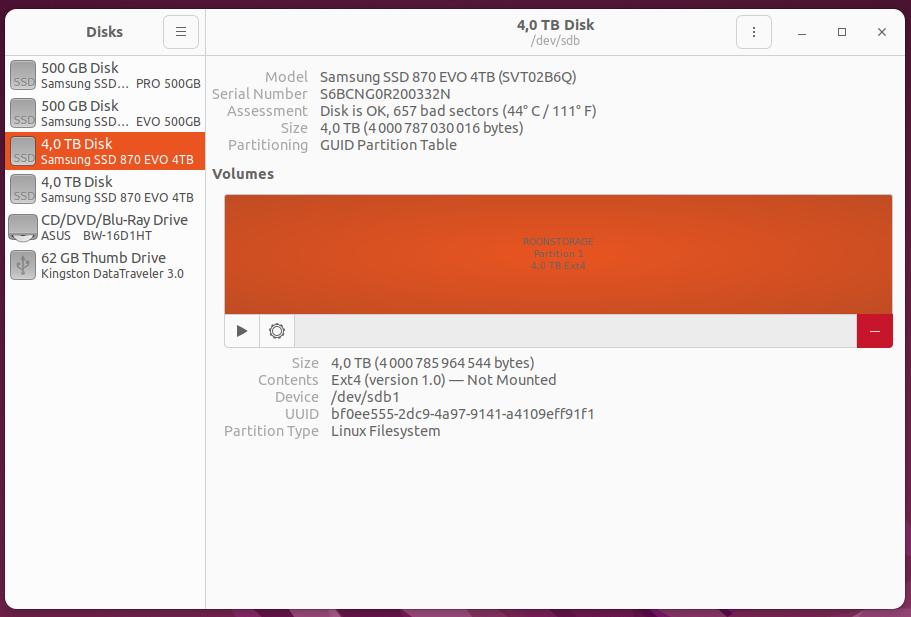
It’s important to distinguish the two, because the OP has the problem that his content (the files) have gotten unreadable, and he looks to a problem with his nice top tier physical storage medium, the 4TB Samsung SSD, for the cause, but the SSD tools (eg. Samsung Magician) doesn’t find any errors on the medium.
But your content can go bad (get corrupted) without any fault or defect of your storage medium.
Unless you have a complete chain of error correction storage via ECC RAM in your server / NUC or PC or whatever PLUS an error correcting file system on your physical storage medium, then your content / data can get corrupted and destroyed at any time.
And data does get corrupted, all the time. The more data you have, the more statistically your data will get corrupted. It’s simple math.
You simply MUST assume that statistically your data will in fact get corrupted - through bit flip errors and cosmic radiation.
Additionally, enterprise class storage documents the likelyhood of an error occuring through the media itself, without any defect in the media - how many bits written to the medium before a write error happens. And when an error occurs, how does the medium deal with it (TLER). Notice, the error cannot be corrected by the medium, even if it detects that an error occured.
This is why enterprise storage systems (the whole storage setup) use ECC Memory and Error Correcting Resiliant Filesystems → for example ZFS.
And no: RAID is not error correcting. RAID (a mirror as the simplest implementation) simply protects you from one or more disks failing. It will not protect you from data corruption that occurs in your RAM or in your filesystem and gets stored there with total accoracy, because the medium doesn’t know anything about the consistency of your >content< (data), it simply needs to know if it stored whatever it has been fed accurately, whether that was an unreadable file or not.
The takeaway: if you value your content, your data, your precious music that you spent weeks and months ripping and tagging and storing [I’m speaking about myself!] then your Roon setup will need to run the core on a server/ NUC with ECC DIMMs (error -correction-) and with something like ZFS as the filesystem ( error -correction-) with two or more physical drives (the RAID part of the equation - drive failure resilience-).