If we are going to have a scientific discussion, let’s be more strict:
The noise floor of human hearing is not 0 dB. Young listeners with undamaged hearing can hear below 0 dB over a narrow frequency range from 2-5 kHz; however, the threshold is 73 dB at 20 Hz. 0 dB does not equal no sound, it means that the measured pressure level is equal to the reference (20 micro-Pa). It is trivial to measure far below the threshold of hearing over much of the frequency range even with low cost measurement chain, but it is still relatively trivial to measure below the threshold of hearing across the entire frequency range with a slightly more expensive chain.
A microphone doesn’t measure dB. It generates a voltage in response to a pressure wave hitting the diaphragm. A microphone does not distinguish between different sources. Interpreting the voltage is the data processing part of the chain; the results can be presented in logarithmic form (dB) but the raw interpretation of voltage would be the linear pressure (Pascals).
As I pointed out above, it is trivial for the measurement chain to have a FAR lower noise floor than human hearing. Distinguishing different sources can actually be done in some ways FAR easier than human interpretation. Especially with an array of microphones that can be used as an acoustic camera.
I think the problem here is that you are asserting a number of things that are just plainly not objectively true, which is obfuscating whatever other point you are trying to make.
But… microphone does not distinguish anything. It just converts sound pressure into electric current. It’s quite easy to find one that does so with much higher sensitivity (and lower noise) than what human hearing can do.
Now, distinguishing different “threads” of sounds (cocktail party problem etc.) is quite interesting, very difficult (this is something that was honed by millions of years of evolution, being quite important for survival), and completely irrelevant for HiFi reproduction. You want to get something on the output as close as to what was in the input, not analize the meaning.
I am very much enjoying this thread and this vid on human hearing. Keep it up: For context, I eagerly follow the various related subjects herein but will not join the debate on the kind and degree of perception we humans enjoy or what audio equipment is “best” since that is, and is agreed upon by most of you, subjective. Personal and dynamic. Further context is that I am struggling with hearing loss due to age but moreso on the right side due to acoustic neuroma and working very closely with my audiologist and neurotologist to properly address the current and future state. Knowledge helps with the associated anxiety. The challenge amplified by my being a performing amateur musician and lucky owner of a fine reproduction system in my home. Thanks for this and, if you’ve read this, your everlasting patience.
No, that’s what audiophiles call instrument separation. How easy it is to distinguish details of any particular individual instrument out of the whole. (such things are by the part of development testing of any lossy codec, and is done by real humans using MOS/MUSHRA and similar)
If you want to do that by measurement, IOW, record an orchestra and then ask the measurement system to isolate just a single instrument out of the whole, it is not as easy as it is for human listening to it.
When I want to listen for some errors, I for example focus on leading edge snap of the cymbal hit and consciously discard everything else in my head. Now, with measurement systems it is not as easy to tell the system that I want to focus on measuring correctness of only that specific portion of the sound. In most measurement systems that gets statistically swallowed by all the other non-relevant parts.
This is similar to detecting suspicious underwater activity from all the background noise in the sea. Despite all the technology, well trained human hearing is still pretty unbeatable on such things. Sure, with technology we can help the hearing to do it’s job better.
This is not much different from trying to develop a self-driving car that manages well in a snow storm on completely snow covered roads.
Right, auditory attention is certainly an aspect of human hearing that is challenging to replicate. It is not clear that there is anything beyond minimizing noise and distortion in the audio reproduction system, treating rooms, etc. that can be done to assist with it. Standard measurement stuff, that is.
For instance, let’s say that you as an equipment designer did isolate out that cymbal hit via your trained audio attention and note that there is something off about it compared with a real cymbal crash. You would then look for distortion that might be the source by examining the measurements at each point of the reproduction chain. You might also have found the same issue by just looking at the measurements before your listening sessions. Now, we’ve seen slips in engineering practice by designers who don’t have access to expensive test equipment like the AP, for instance. In some cases, they just prefer distortions (euphonic!) or bloated upper mids (spatial!), and that’s their schtick.
But, if you have the equipment and acumen, and you do not see any obvious reasons in the measurements, then you have to invent an exciting new theory of what is happening and, yes, measurements that help you develop a solution strategy. Like I said about cable promoters, that can become an awesome new value proposition for a product, possibly protected by IP, but it has to be ultimately measurable.
Think about it in another way. That you know the differences mathematically perfectly well, but measuring those differences by traditional methods is very difficult. And you know how to analyze those mathematically, but regular measurement equipment doesn’t do such methods.
Well, such an abstraction is a bit inert for me. I can think of specific new problems, theories, and measurement regimes in the history of modern audio reproduction like jitter and class D problems. Each follows my script of discovery, measurement, and solution. It’s very concrete.
It is not abstraction, it is reality. Of course you may have not personally encountered it depending on what you are working on. But that doesn’t mean it doesn’t exist.
Yes, like class-D suffers from aliasing and slew rate problems etc. But these are not covered by your typical SINAD measurements. And so forth.
We may be talking past each other at this point since the topic has to do with measurements in general and not simply SINAD. You know well enough the range of measurements that go into evaluating DACs, amps, AVRs, headphones, and speakers. Each has been developed to capture the currently deemed important and distinguishing characteristics, and different reviewers look at different features for experiential and professional reasons.
So if there are critical audio performance measurements that are insufficient because a designer such as yourself has a cluster of hypotheses with the concomitant mathematics backing them, then the designer is left with a curious series of choices: how to choose algorithms, components, thresholds, timings, etc. without having the capacity to measure the effects of those choices. As an engineer and scientist I don’t proceed that way nor do I think it creates a compelling value proposition as an entrepreneur. We should show rather than proclaim our golden ears are the arbiter of truth.
You said that the existing traditional measurement are enough to tell all. And I tell they are not.
I’m pretty sure people designing ESS and AKM chip internals will tell you the same. In fact I’ve seen presentation by ESS telling precisely that.
AK4191 has four different modulator options. I’m curiously waiting your exhaustive analysis of the differences. I can already tell that the differences are not particularly relevant to constant tones, but rather more complex signals that are constantly changing at fast pace (like music).
Obscure response and unnecessarily argumentative! To reiterate: there is no evidence that there are relevant properties of audio systems that are not measurable but only hearable by golden ears. Indeed, it is irrational to claim otherwise since evidence requires, well, evidence. For engineered audio systems, evidence means measurements. Well, in fairness, massive large-scale ABX listening also qualifies and, yes, it is a measurement. An individual’s claims are just a passing curiosity.
I am 100% certain that ESS and AKM engineers designed and tested their chips to achieve certain measurable goals like transparent reproduction if properly implemented. Their presentations and data sheets will shine a light on how they reached their designs goals and should shed additional light on the specific applications they envision for the different modulators. It is possible that the designers are well-aware that the different modulators will have no audible impact on the output, too, but provide them due to demand and/or market differentiation.
So I’m still at a loss what you are arguing about?
Audiophiles… the people who believe in $500 magic directional fuses?
But seriously. instrument separation, soundstage, and other lifted veils occur in your brain. I am not aware of any piece of audio equipment that does, or needs to distinguish between the first violin and a glockenspiel in an orchestral recording.
If two sources (let’s say DACs) produce different “instrument separation” or “soundstage” or something else (under a blind test, of course) holding everything else, like speakers and room, equal, then obviously the electrical signal going to those speakers must be different. That difference, if it exists, can be measured, that’s not that difficult.
Somehow though, when it comes to actually demonstrating that there is a difference in signal, and that it can be heard in a controlled experiment, there’s a lot of handwaving and “trust me, bro” from interested parties, but no demonstration.
If DAC 1 and DAC 2 provide widely different sound, surely someone could scope the difference between outputs.But somehow this usually fails at the stage of telling 1 from 2 with your eyes closed…
mjw
(Father! Father! Resist not! Let us destroy the core! Set us free!)
53
You appear to be suggesting that if you could pour a sound recording into a glass, that there’s some unknown ingredient that can’t be identified.
I don’t believe there is any evidence to support this. But, even if it were, it is irrelevant, since we can reproduce the same “drink” every time.
This seems to be argument for arguments sake, with no relevant facts presented, and buck passing the burden of proof to those on the wrong side of the argument.
But will you be able to do same analysis from the DAC output? Doing Matlab → AK4191 → Matlab would work fairly well. You get the 5.6/11.2 MHz output data to look at. With ESS that is much more difficult since you don’t have access to the data between modulator and conversion section. From analog outputs will be much more difficult.
Doing numerical analysis of the thing is very possible and what is typically being done, especially when you have all the math at hand. Once the MHz data stream has been converted to analog, doing the same kind of analysis is rather difficult. The information is still in there, but doing kind of reverse conversion from analog back to MHz rate digital is what will fail since part of it has been smoothed out by the conversion stage and analog filters.
It is not something you just do FFT on in AP to look at the result, since FFT doesn’t work for what I’m talking about. It works only for one domain of aspects, there are a lot more.
Or that they are well aware that they have audible differences while all measuring good.
You can always measure differences, even between two units of same make and model. Then you just need to figure out which of the differences cause the audible ones.
For some fun, you can watch for example this, although it contains a lot of advertising too:
Now try doing the above analysis from the DAC analog outputs.
This is also kind of stuff I do all the time when developing my algorithms. And that is not something you do with AP.
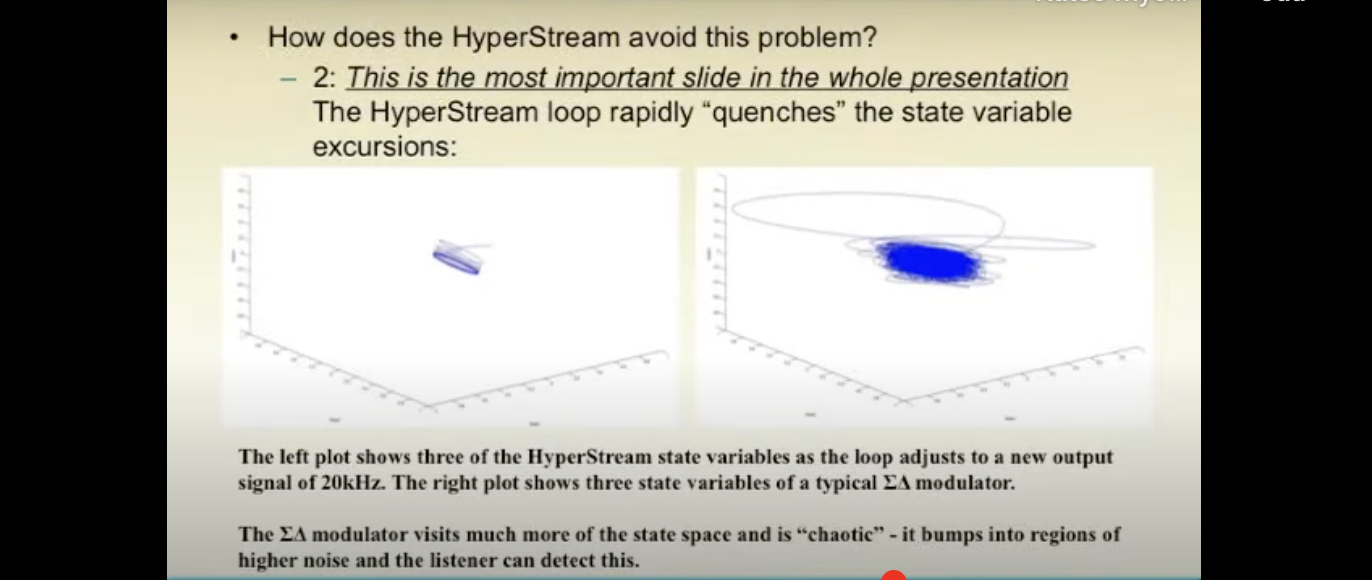
I also do a lot of measurements, usual and less usual all the time. So I know for example that Hyperstream II (9038PRO, etc) can go a bit nuts and spit out fairly strong 1 / 2 / 3 MHz tone under certain input signal conditions.
Josef Manger (Manger Audio) has published two papers on the subject, particularly in relation to loudspeakers: The hearing phenomenon and Acoustical Reality. They may be of interest.
Or, as the somewhat recent discussion about a certain much-delayed product demonstrated, switching them might be broken, but both the designer and golden-eared customers would still swear that there is a night and day audible difference between them.
I have yet to see any rigorous proof of there being an audible difference.
Perfect. We are at least in agreement that it is possible to measure even minute differences between two samples of the same device, let alone clearly humongous differences between devices exhibiting night and day differences in sound.
So let’s measure the difference between two samples of DAC A, ensure that they are indistinguishable in listening test, then measure the difference between DAC A and DAC B which is allegedly distinguishable, and there we have some reasonable baselines for what is and is not audibly different. No need to worry about any fancy brain proessing of instrument separation or anything.
Of course we would need to demonstrate first that A and B are in fact distinguishable in a blind test…
I don’t think even Rob Watts claims to be able to hear into the MHz range…
But to get back to the original topic, it seems that anything that is audible is also measurable without needing resources of a clandestine nuclear weapons program, even if it may not be expressible in a single SINAD number (although there is some string lasck of experimental proof that it is in fact not).
I think there is a very good Upton Sinclair quote about this.
I don’t remember listening to those speakers before, I really look forward to listening such. (so far, I’ve been mostly preferring ribbon/AMT drivers when it comes to tweeters for example)
P.S. With convolution based correction you can correct the transient/phase response to a limit. It won’t make gold out of coal, but it can certainly make things a lot better.