Hi, @mjw
This is longish. Sorry. I recommend a full read 
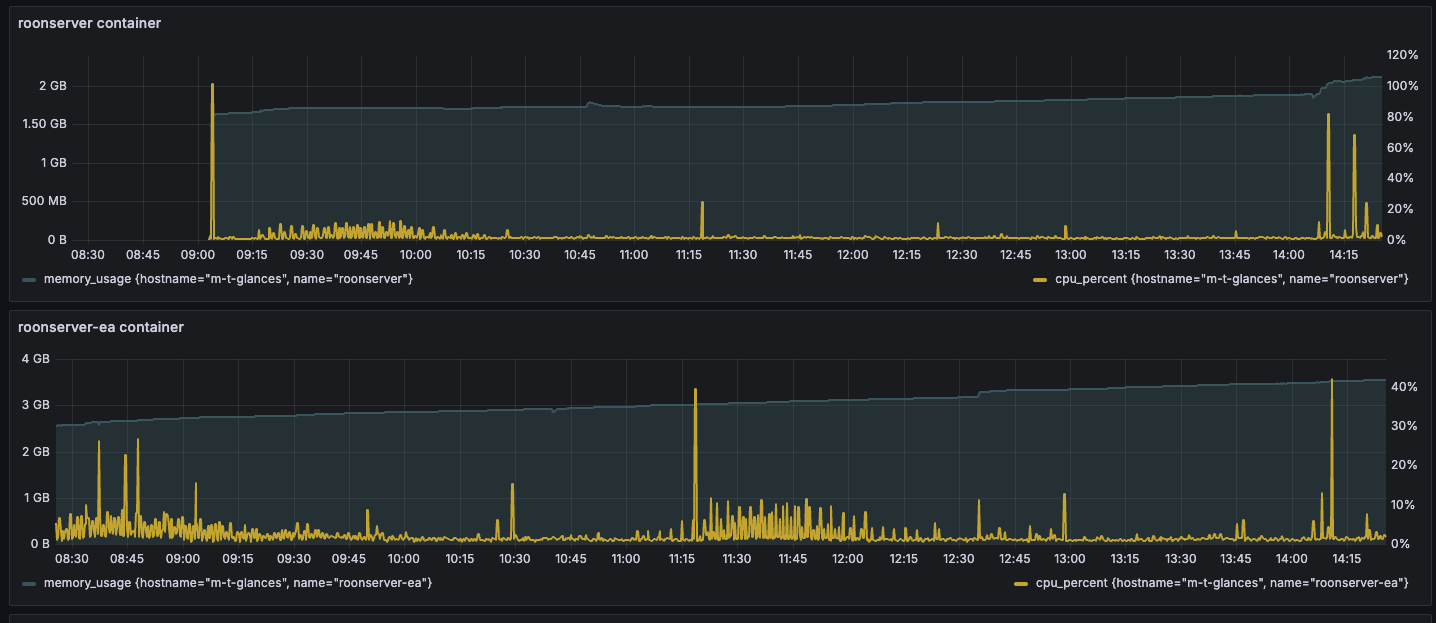
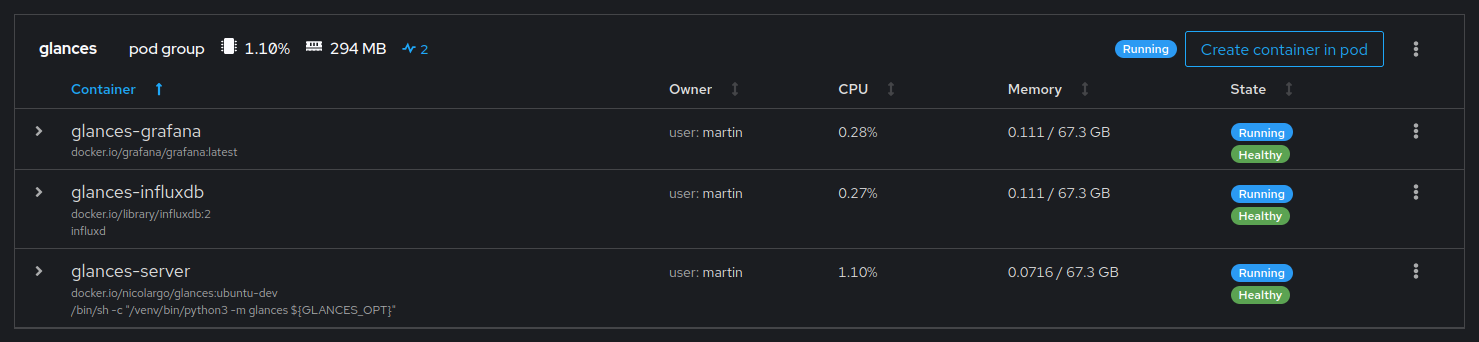
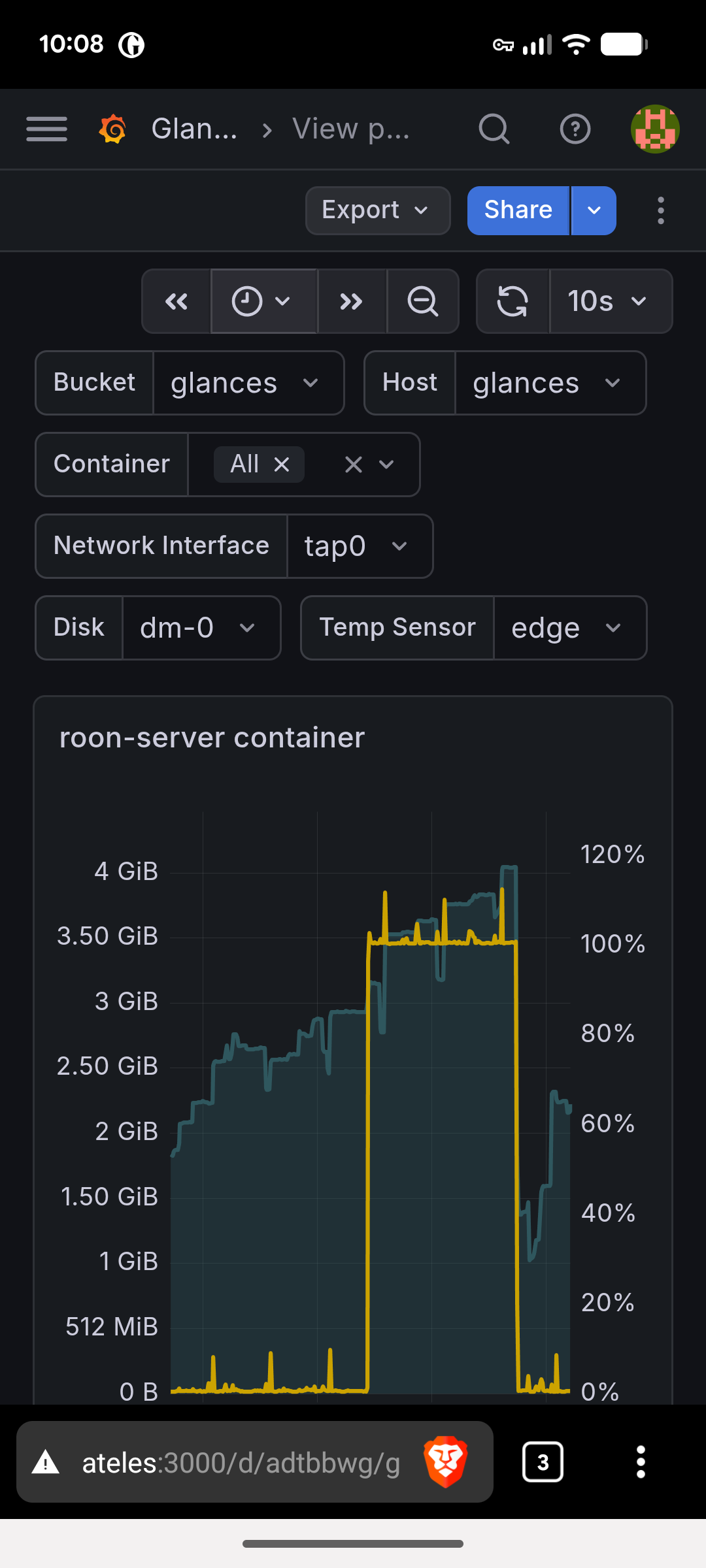
I’ve been looking at the official Roon docker container - comparing it’s characteristics to my self-built container. In the process, I saw discrepancies between container memory consumption as reported by the Docker API, what I was seeing in a version of Glances that I run to look at the TUI UI, and what I was seeing in my Grafana dashboard which based on the stack yours is, which has its own version of Glances pushing into Influx.
Here’s the short story - for reasons I don’t recall, I had the telemetry stack’s version of Glances pinned to an old version (4.4.1). As of today, Glances is at 4.5.4.
The version I was using was significantly under-reporting memory usage. It should have been reading stats from Docker and pushing them into Influx. But the value it was pushing for memory_usage was significantly low. About 500MB in the case of Roon.
This is fixed in the latest version. Moving to “nicolargo/glances:latest-full” caused that value to align with what the current version of Glances shows in the TUI and what Docker itself reports if you invoke with something like:
sudo curl -s --unix-socket /var/run/docker.sock \
"http://localhost/containers/roonserver/stats?stream=false" | \
jq '.memory_stats | {usage, limit, stats: {anon: .stats.anon, file: .stats.file, inactive_file: .stats.inactive_file, active_file: .stats.active_file}}'
Unfortunately, that’s not the whole story. As far as I can tell, Docker’s reported “usage” actually includes inactive memory, which is separately reported as “inactive_file”. Glances pushes a number of memory datapoints into Influx. My dashboard graphs “memory_usage” and I think yours does, too.
The problem is that this includes the portion of memory which is reclaimable page cache and, realistically, it probably shouldn’t. The “fix” is to subtract it out and graph that as “memory_usage - memory_inactive_file”.
It gets more complex, though, because the extent to which this matters is going to vary significantly by system. My system is TrueNAS with 128GB of RAM, most of which is dedicated to ZFS ARC. On this system, inactive_file appears to almost always be 0. I literally see just one instance of a non-zero value over the past day and, strangely, it’s for the Grafana container.
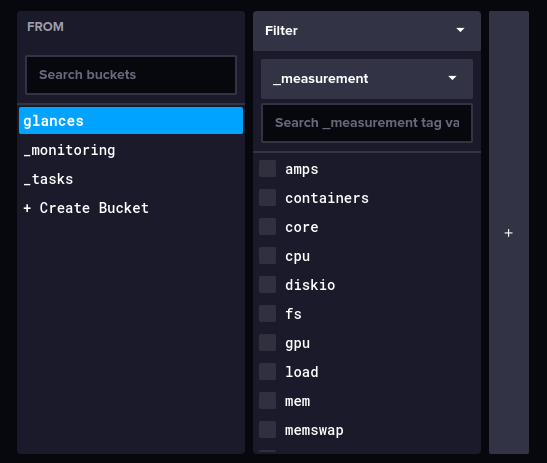
If you want to do a quick test in Influx, you can run a query like this:
from(bucket: "glances")
|> range(start: -24h)
|> filter(fn: (r) => r._measurement == "containers")
|> filter(fn: (r) => r._field == "memory_inactive_file")
|> group(columns: ["name"])
|> max()
If you see non-zero values, the most straightforward fix would be to modify the Grafana query to subtract it out (and / or add it to the Grafana graphs).
I know that was long but I put you on this dashboard path and I feel responsible if you’ve got bad data