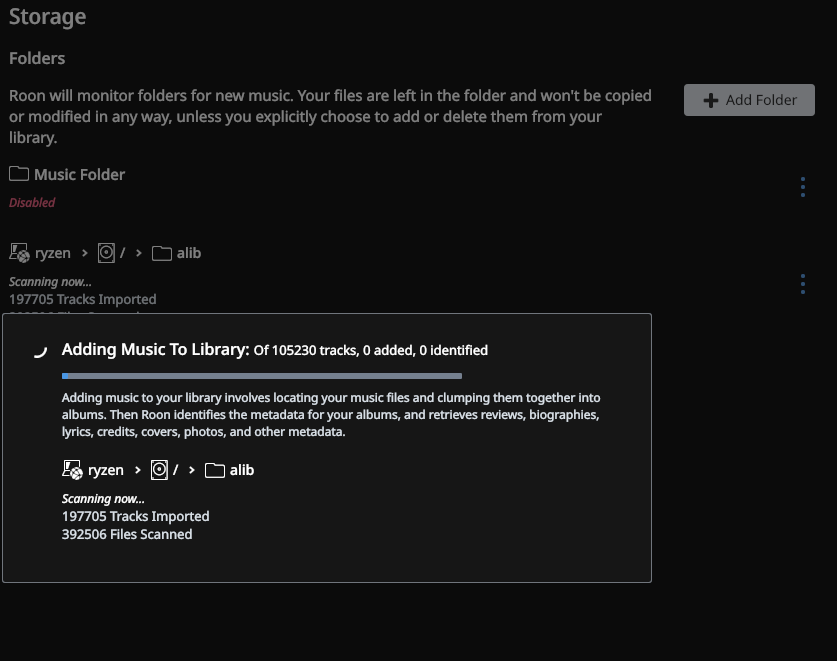
Yesterday I switched Roon Core to my Ryzen based desktop with the underlying music located on a server on my network, accessed via NFS. This morning I fired up my desktop PC without the NFS shares being online and Roon effectively dropped the entire library - bringing up the machine hosting the underlying music triggered a complete rescan and reimport of the library.
Unless I’m mistaken the current behaviour means that if a user has a music drive fail they automatically lose their Roon database too.
Would it not be possible to pause the DB under such circumstances and have the user confirm “trash and start over” only if necessary vs bringing the storage online and then bringing the database online too?
When the underlying files in a Roon watched folder are not available on the file system the albums are no longer displayed in the GUI however, nothing is removed from the DB…
My files are on a QNAP, on the odd occasion I’ve fired up the Roon Core without the NAS being online,
I’ve seen this … but after switching on the NAS Roon repopulates the GUI, no files to clean up and all is well.
I’m wondering if somehow Roon now thinks these file are on a different path and thus has reimported (as new music) them rather the reinstating them.
One for @support, so I’ve moved your topic over to the support category of the forum.
Yip, that’s exactly how I’ve understood it, and I could confirm the same visually. The rescan and reimport started a soon as I ran:
mount -a
causing the NFS shares to be mounted to the same mountpoints they were mounted to the previous night. So whilst the DB was intact Roon was intent on redoing the work it took the previous day to do.
Actually, I’m not prepared to leave it running overnight to redo all this and thrash my ssd needlessly. I’ve stopped and disabled core on this machine for the moment.
I suspect it’s an oversight/bug in Roon possibly linked to an umounted NFS share appearing empty as opposed to a SMB share being inaccessible when the target is offline.
What kind of OS is the Ryzen running, is it Windows and if so which edition?
What is the network setup like? What is the model/manufacturer of your networking gear and how is your Core connected and how are your NFS shares connected?
Where is the media stored? You mentioned NFS, but what is it on, a NAS, another PC? If on another PC please provide details of the PC and how it’s connected to network.
How can we reproduce this behavior on our end? What are the exact steps we need to take to get this reproducible in the lab? From your post it seems like:
@noris, I’d have to recreate the issue and copy the logs because in my setups the logs are written to tmpfs rather than SSD. I’ll point to a small subset of my library, trigger the issue and grab the logs.
QA spent some time trying to reproduce the issue this week, but they have not been able to get any consistent results so far. We’re still looking into this, if we have any further questions I’ll be sure to let you know.