I am starting a new thread to discuss the measurements and [single-]blind A/B listening tests of the Diretta protocol, as a follow-up to the original thread:
I divided it into sections, so that they can be easily referenced in the discussions. There will be two main sections: measurements and listening tests. This post presents the former, with the latter to come in a later post when completed.
I would like this to be a fact-based, technical discussion of Diretta. If you are interested in a purely subjective take of the subject, please see the original thread.
0. Setup
This is the diagram of the setup used. It is based on @David_Snyder’s instructions, which you will find in the original thread.
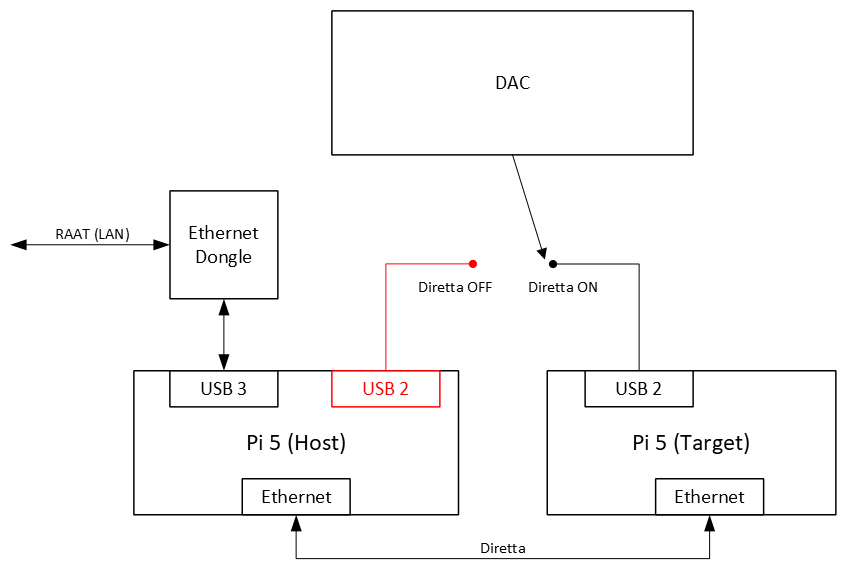
The host box on the left is connected to LAN through a USB Ethernet dongle and is visible to Roon server through RAAT protocol. The dongle is necessary to create an additional Ethernet port on the host, as the onboard port is used to communicate with the target box on the right through Diretta protocol.
In a normal, Diretta-only setup, the red path is missing and the DAC connects to one of the USB 2 ports on the target box (the “Diretta ON” connection in the diagram). The signal path in this case is:
Roon → [RAAT] → host → [Diretta] → target → USB DAC.
The red path was used to be able to make measurements with Diretta protocol out of the picture. In that case, the DAC connects to one of the USB 2 ports on the host box (the “Diretta OFF” connection in the diagram), and the signal path is the usual Roon playback path:
Roon → [RAAT] → host → USB DAC.
(There was no USB switch used in the setup; switching was done by simply unplugging the DAC from one of the USB ports and plugging it into the other.)
The DAC used is a Topping D70.
1. Measurements
This section is further divided into two: power rail measurements for both 5V and 3.3V rails and DAC output measurements.
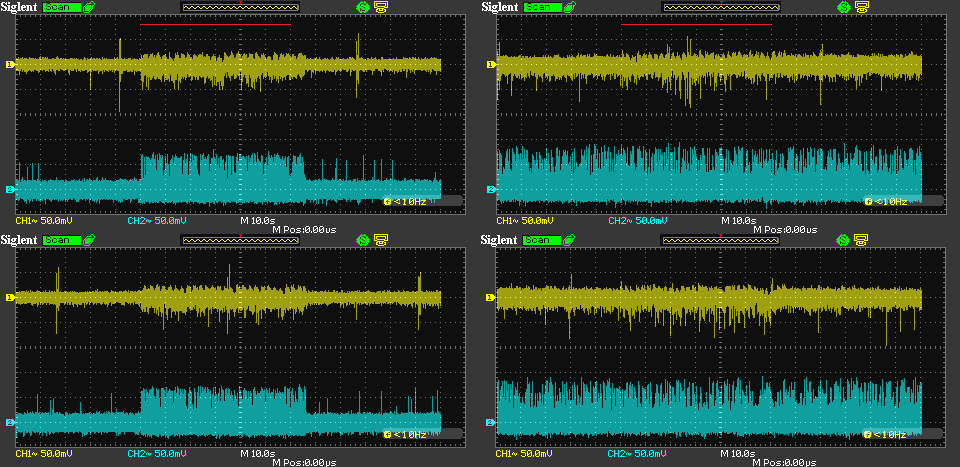
In all images, the diagrams on the left show the target box - i.e. with Diretta - and the ones on the right the host box - i.e. with RAAT only.
1.1 Power Rails
1.1.1 Power Rails Time Domain
These diagrams show the waveform of the power rails (yellow for 5V, blue for 3.3V) over a 17-or-so seconds at a time. I used AC coupling here so I can amplify and put both on the same screen. One time division is 10s, one voltage division is 50mV.
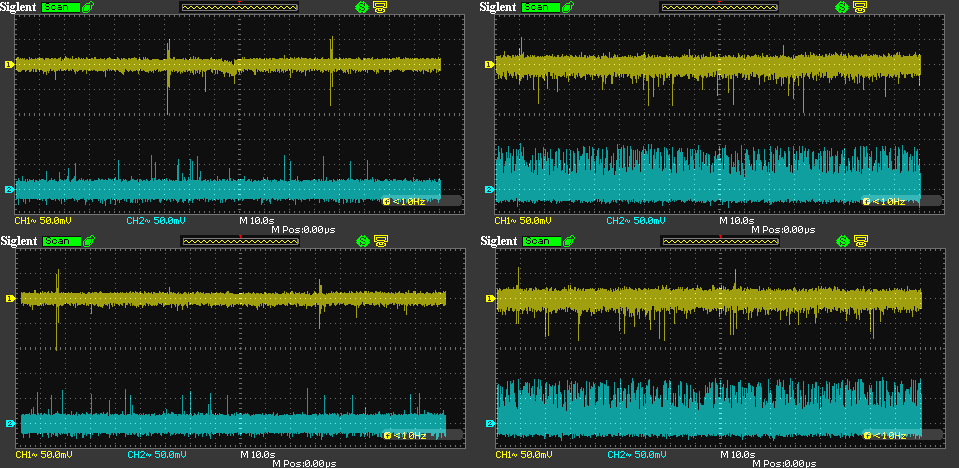
Diagram above was captured when nothing was playing. Diretta is definitely quieter here, with an amplitude of the noise is roughly half of that of the host for both rails. This is not exactly a fair comparison though, as host box’s USB3 port connected to the Ethernet dongle was working all the time, while there was no USB (and barely any network) activity on the target box. Still, spikes of activity can still be seen on the target. The 5V spikes are as high as the ones on the host (roughly 150mV pp), and the ones on the 3.3V rail, although smaller, appear quite random.
Same as the previous one, but when silence (more exactly, 32-bit dither) was played. The red horizontal bar at the top of the diagrams shows the playback interval, roughly one minute. We can see the noise on the target box rails “come alive” during streaming, while there’s not much change in the noise pattern on the host. The noise amplitudes on the target are now almost the same as on the host, although this is still not a fair comparison, since there’s one USB port working on the target and two USB ports on the host. Most interestingly, the spikes on both 5V and 3.3V rails on the target seem random to me.
(You can see that Roon is streaming silence for about 5 seconds after playback is stopped. That’s the time after which the signal indicator light “turns off”.)
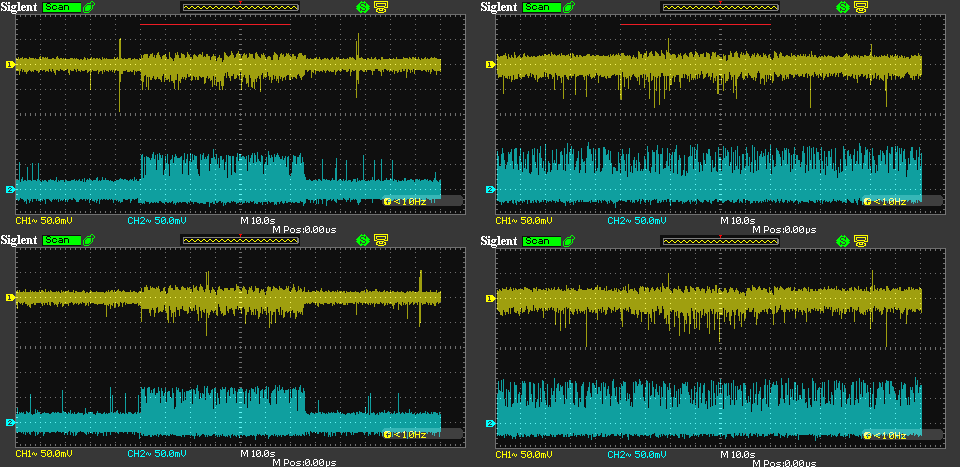
Same as the previous one, but when death metal is played instead of silence. (I used the title track from Fractal Generator’s Macrocosmos album. That is loud!) I was curious if the streamed data had any impact on the noise. It doesn’t. I think it’s plenty apparent here that the bits that are streamed cannot be called “music” in any shape or form; they may sometimes be more ones or more zeroes, but the physical layers involved in transmission work just the same.
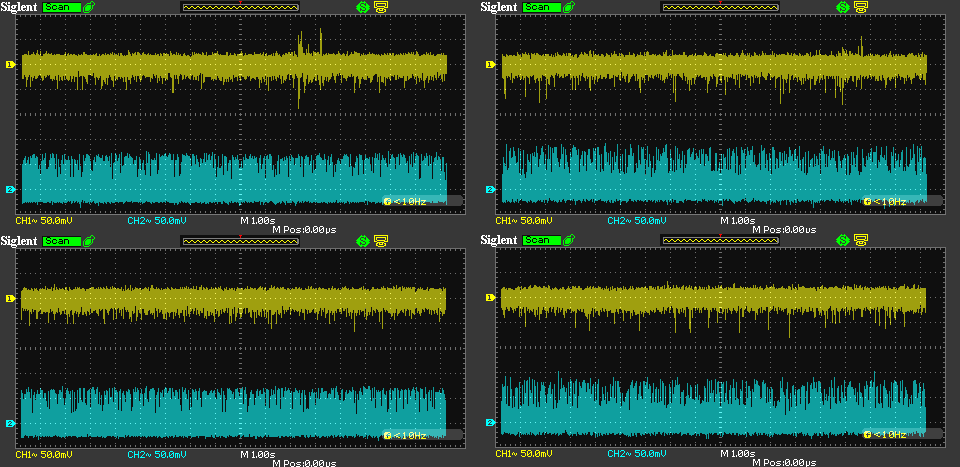
In the capture above, I zoomed 10x on the time axis to get a more detailed noise waveform. The division is now 1s and the span is about 17s. The noise on the target still looks quite random to me. The big spikes appear to happen more than one minute in between.
Apart from the slightly smaller amplitude of the noise on the target relative to the host - which is most probably due to one less USB port being active - I don’t really see anything that sets Diretta apart from RAAT. Let me know if I am missing something.
(I will perform another measurement of a RAAT-only box using only the onboard Ethernet port and with only one active USB, to see if it brings the noise to a level comparable to the one on the target box.)
1.1.2 Power Rails Frequency Domain
The following images show the spectrum of the power rail noise. I used DC coupling for these, to make sure I didn’t miss any low-frequency noise.
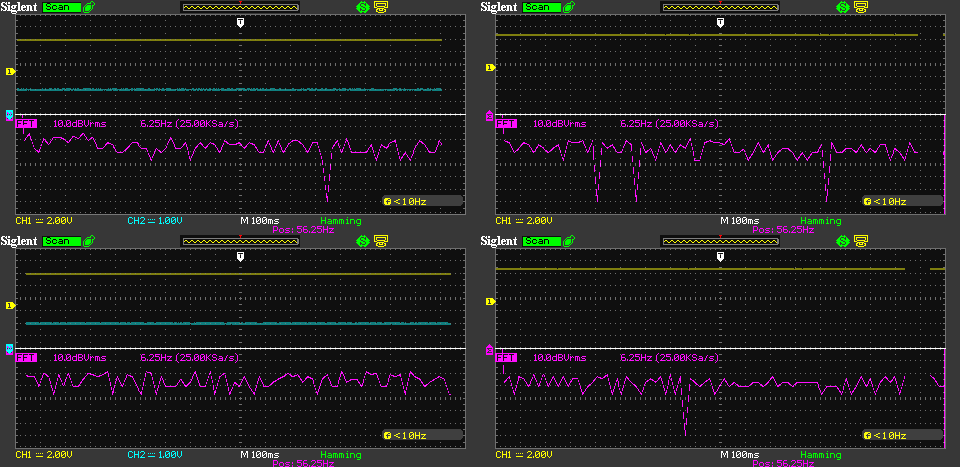
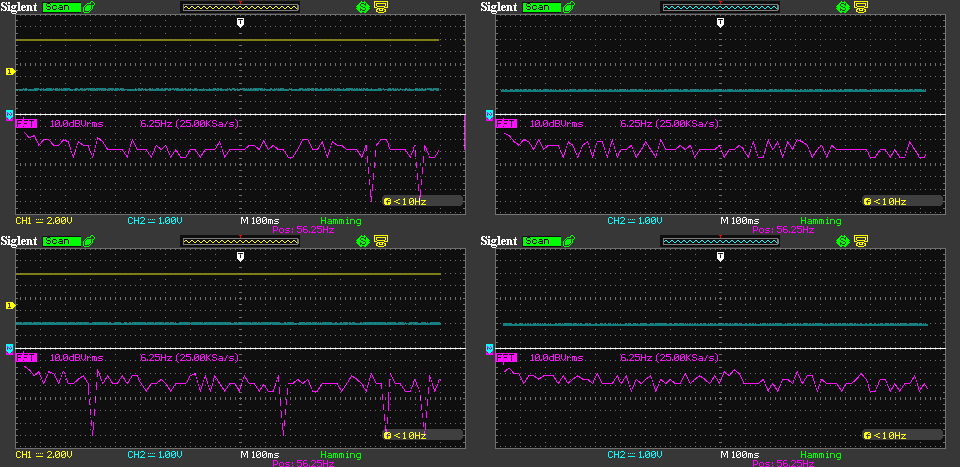
The image above shows the spectrum of the 5V rail noise between zero and about 106Hz. One horizontal division is 6.25Hz. As usual, target box is on the left; top graphs are captured during silence playback and the bottom ones during death metal. I am not seeing any significant upward spikes here, or any difference between the two boxes.
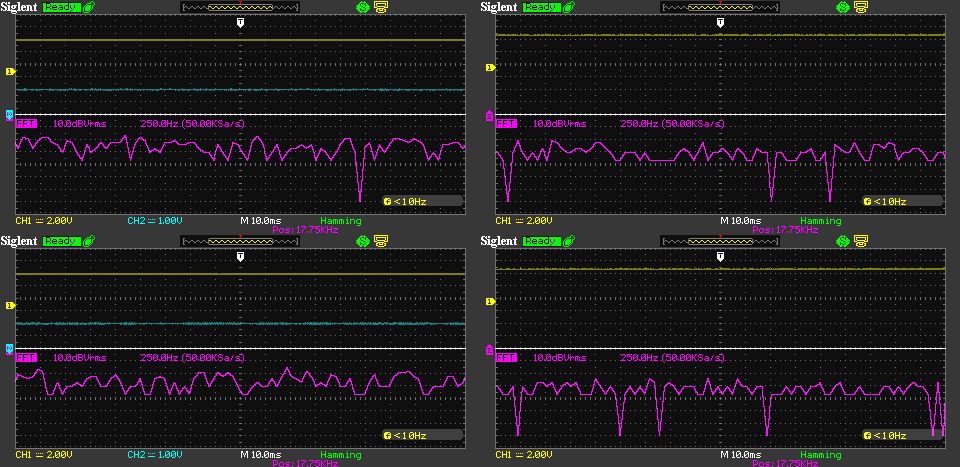
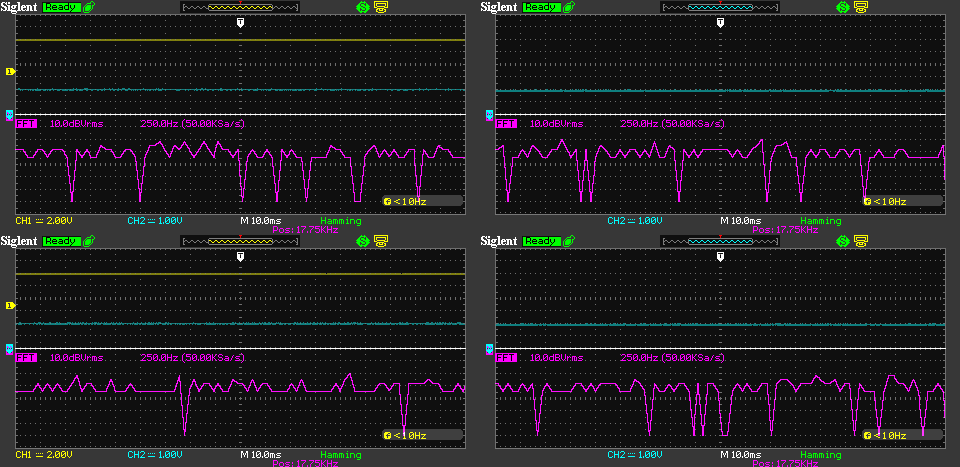
This image shows the 5V noise spectrum between about 15.5kHz and 20kHz. One horizontal division is 250Hz and the center of the frequency axis is at 17.75kHz. I’m not seeing any relevant spikes or differences here either.
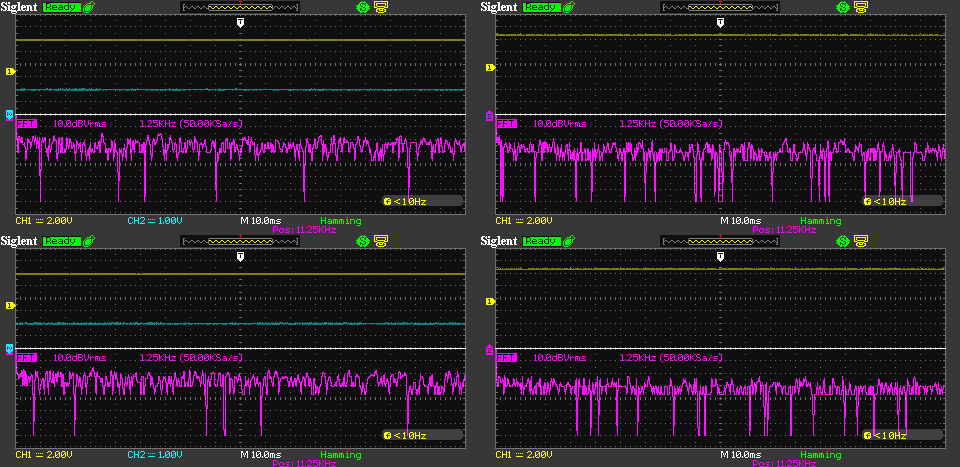
This one captures the full spectrum between zero and 22.5kHz, so it fully contains the audible spectrum. One horizontal division is 1.25kHz and the center of the frequency axis is at 11.25kHz. Looks the same to me.
The following 3 images show the same thing as the previous 3, but for the 3.3V rail. Let me know if you can spot any differences between the rails or between target and host.
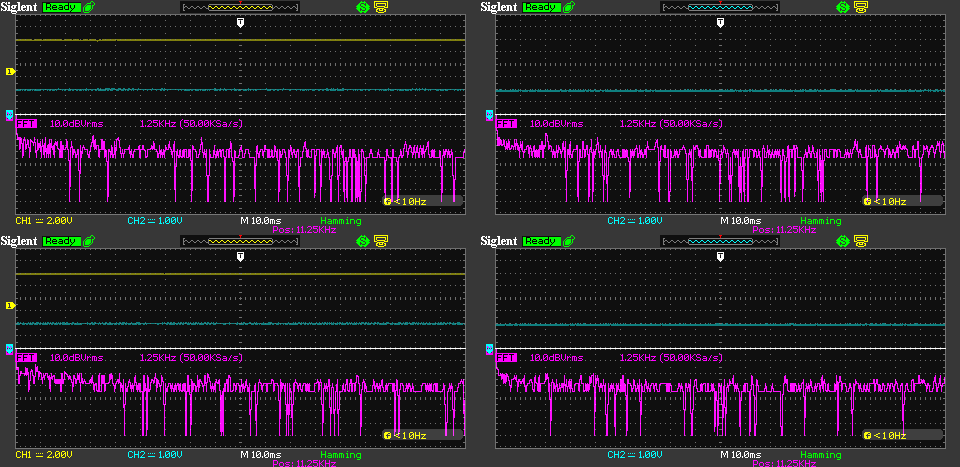
This concludes the power rails measurements.
1.2 DAC Output
Now comes the interesting part: measuring the actual output of the DAC! At the end of the day, this is what we are actually listening to - if of course we ignore all the artifacts of the analog chain. Again, the left side in each image is through Diretta and the right side through RAAT only.
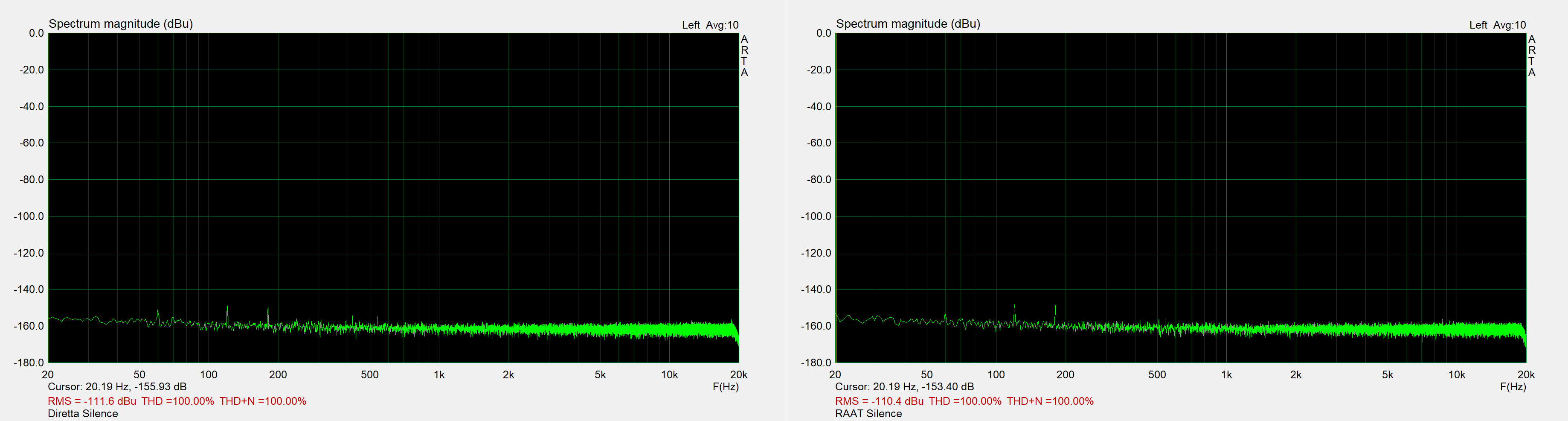
The image above shows the output of the DAC when silence (32-bit dither) is played. This shows the DAC at its most silent; I think the zero-detect feature of the chip is muting the output.
I think this is the best proof that Diretta’s rationale for a two-box-solution falls flat on its face. Every single component of the Topping D70 DAC is under one single box, including the power supply. This means that there’s a 110V/60Hz “signal” entering the box at all times. It’s a very high voltage at a very audible frequency. Still, the only indications there’s a PSU inside are the tiny peaks at 60Hz, 120Hz and 180Hz. The highest is somewhere around -150dB! If the PSU noise is suppressed to this degree, what do you think happens with EMI/RFI noise measured in millivolts and extending into higher frequencies? The fact that everything is in one single box doesn’t seem to be of any practical consequence.
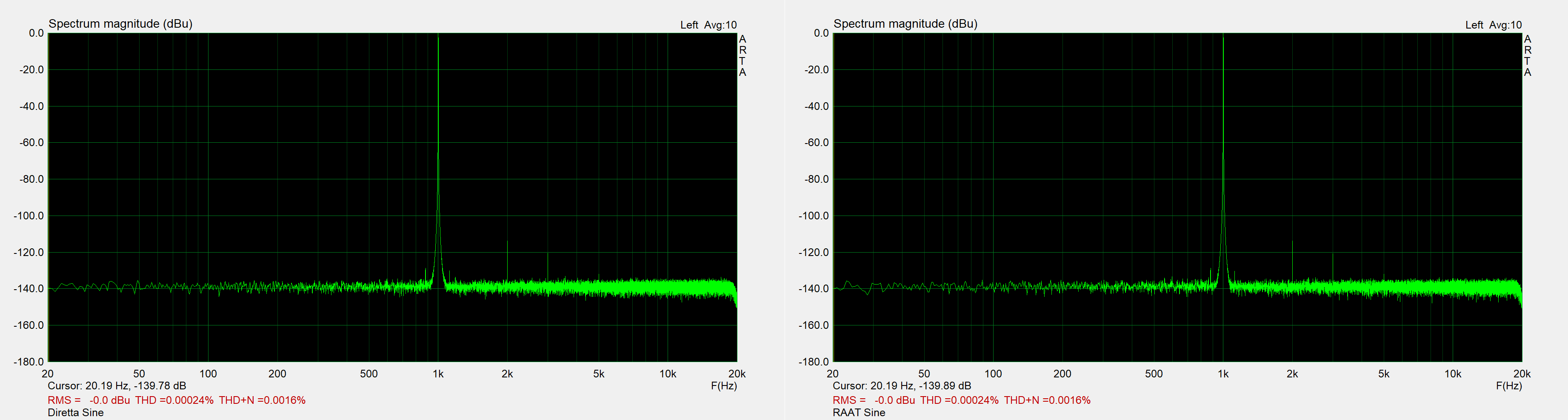
This are the output spectrums for a 1kHz sine. They look the same to me, and the THD+N are the same for Diretta and RAAT.
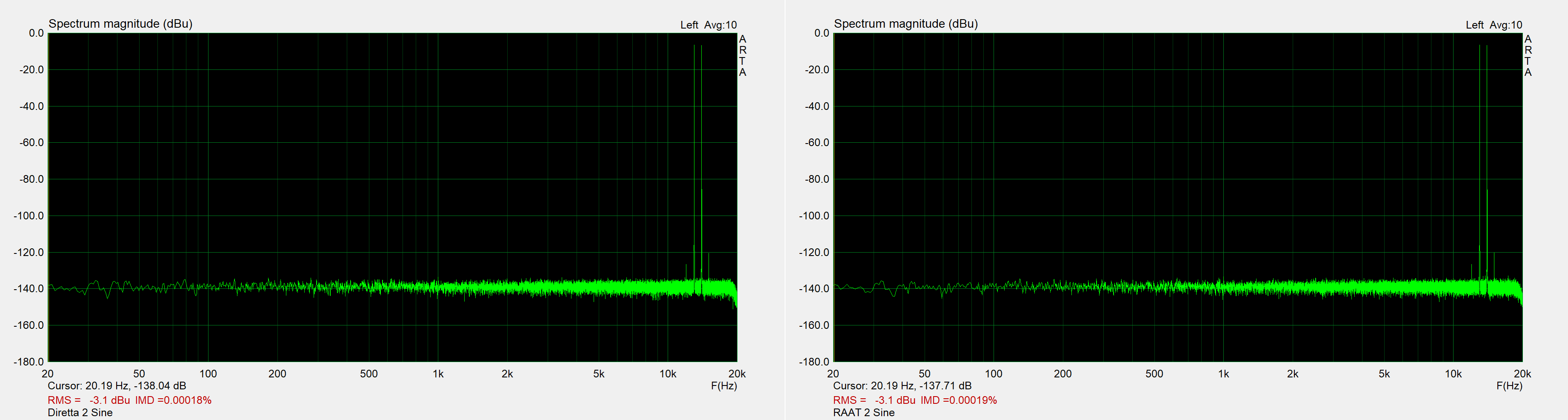
This is the 2-sine intermodulation test signal. Again, I see no notable differences.
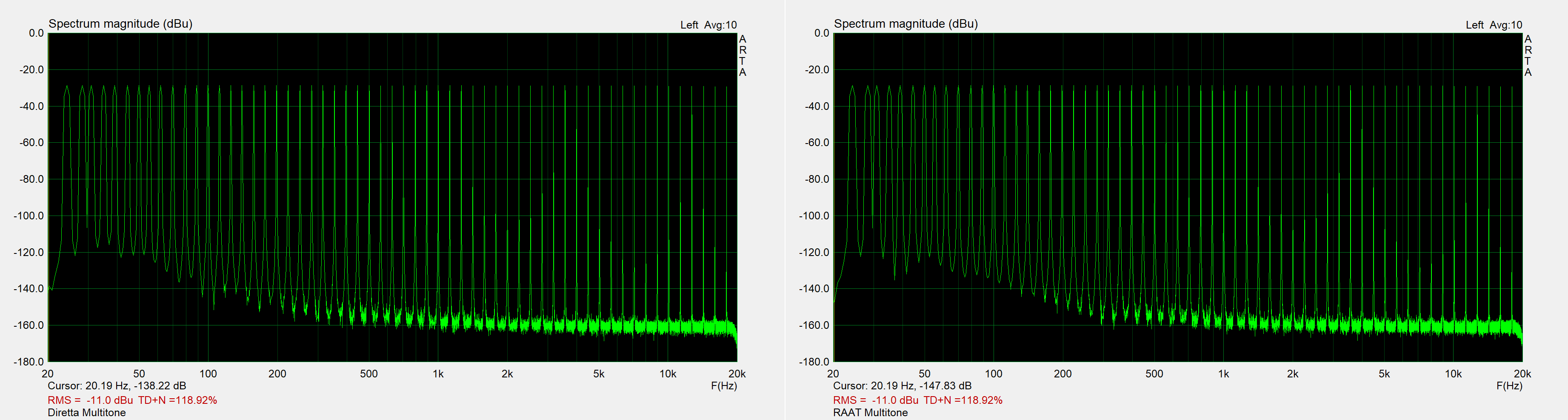
Same for the multitone test signal.
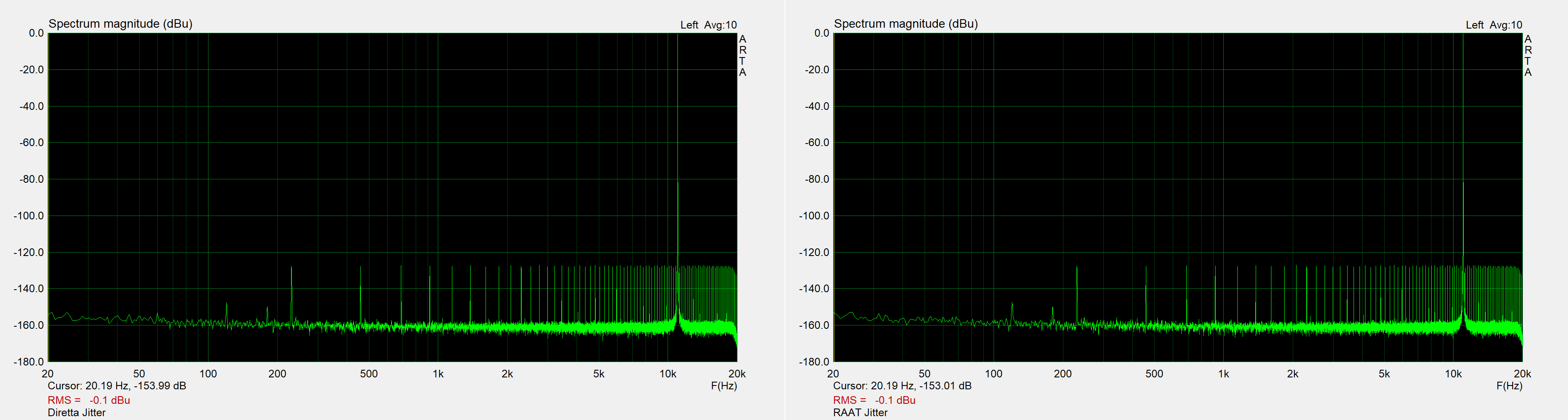
Same for the jitter test signal. All the artifacts are tucked well below -120dB in both cases.
1.3. Conclusion
According to measurements, the Diretta myth seems BUSTED.
2. Listening Tests
For these tests, I asked my two sons to listen the two boxes - red and black - using their choice of tracks, and tell me which one they prefer, if any, and why. I told them to do rapid switches first with same songs and without touching the volume to see if there were any sound quality differences, then to listen for 20 minutes or so to one album on one box and then to the same album on the other, to see if there were any “long term” differences - whatever that meant. Besides those, I let them experiment in other ways, should they choose to.
We did this 3 times. I told them I did some small tweaks and/or upgrades between rounds, so that they treat each round as a new experiment. That wasn’t a trick, as I did make changes, but to add some suspense, I’ll explain later on what those were.
I’ll refer to my 26-yer-old son as “Kid A” - yes, he’s a Radiohead fan - and to my 20-year-old one as “Kid B”.
Kid A is non-conformist, to say the least, so he probably didn’t follow my instructions about how to listen. He seemed however more involved in the experiment and kept asking if he got it right and trying to read my mind, so I had to convince him there was no right or wrong answer. Not sure if that worked…
Kid B is an even bigger Radiohead fan, but he got to be player 2 because of age, and also because “A” and “B” happen to be their first name initials - more or less. I think he followed my advice about how to listen and did not come with variants.
Both of them felt some frustration with not being able to do rapid switching, and none of them felt that the “long term” listening was relevant. Kid B did mention listening fatigue, not in the sense that one box was more fatiguing than the other, but because the longer listening to one box skewed the results of the other box’s evaluation.
Finally, I’ll throw them under the bus and say that both of them treated this as some kind of chore, which is the main reason it took this long to finish. The actual rounds didn’t take more than one hour each.
These are the results of each round of listening.
2.1 Round 1
2.1.1 Kid A
Initially, after listening for a bit with his usual cans - a midrange Grado - he preferred the red box because it allowed him to turn up the volume more than with the black box, and he likes his music on the loud side - too loud if you ask me. He then switched to our Audeze cans and changed his preference to the black box. (He mentioned he didn’t think the change was because of the choice of cans.) He still thought he could use more volume on the red box, but that it was because the sound was tamer and the instruments less differentiated and more “equalized”, as opposed to the black box, where the instruments’ levels were more individualized and thus more separated. The guitar did “shriek” above other instruments, which was both good and bad, but overall, the black box had a bit better soundstage.
2.1.2 Kid B
Kid B did not perceive much difference between the two and said that, if he had to make a choice, he’d prefer the red box as being “clearer”. He didn’t elaborate beyond this. He used the Audeze cans for all rounds.
2.2 Round 2
2.2.1 Kid A
This time around, he didn’t find that much of a difference between the two, but he stuck to his preference for the black box, for similar reasons. He used his Grado cans for this round and the next.
2.2.2 Kid B
Same conclusion as the first time around: if anything, the red box had a small clarity edge over the black box.
2.3 Round 3
2.3.1 Kid A
This time around, he changed his preference back to the red box, but said that he didn’t really like any of the boxes, felt like it was a really big step down from previous two rounds on both, and the differences were more pronounced in terms of volume: red box could again go higher volume than the black box, but he preferred it because there was no other difference, and the black box was over the edge in terms of loudness.
2.3.2 Kid B
Same conclusion: red box wins, but only if we really had to make a choice.
2.4 Red Box - Black Box
Before you draw any conclusions, I have to clarify what changes I made to the setup between the rounds. I made absolutely no changes to the OS or the protocol versions.
-
Round 1: red box was Diretta, black box was RAAT
-
Round 2: red box was RAAT, black box was Diretta. I literally swapped the boards between the two cases.
-
Round 3: both boxes were RAAT. I re-flashed both SD cards with AudioLinux, installed only Roon bridge, didn’t apply any tweaks, and connected them both to LAN. In other words, the two boxes were simply identical.
Note that I didn’t do this to trick anyone; I just wanted to eliminate potential biases unrelated to the sound, e.g. the appearance of the two boxes, their positions, the choice of device names in Roon etc. Since they did their own switching, it wasn’t a completely blind test.
2.5 Conclusion
If you go back to the 3 rounds and replace “red box” and “black box” with the corresponding “Diretta” and “RAAT”, as explained in section 2.4, I don’t think anyone can unequivocally say that either participant had a clear preference for Diretta or RAAT.
- In case of Kid A, what I found most interesting is that he still found significant differences between the boxes in round 3, when they were identical. When I told him that, he didn’t believe me, so he had me measure the output level on the two boxes to see if they were indeed the same. He admitted it could have been because he used different sets of songs for each round. For me, the takeaway is clear: when you ask someone to find differences, it’s likely they will find them, and sometimes, those “differences” are not even subtle.
- In case of Kid B, what’s interesting is that the red box won every time, no matter what it really was. Whether he liked red more than black, or the fact that “Diretta” was on the left, or whether he preferred the name “Diretta” over “Indiretta”, I can’t tell. What I can tell is that he felt like he had to make a choice, and the choice, once made, didn’t change.
According to listening tests, I can’t reject the null hypothesis, so I declare the Diretta myth BUSTED.
This concludes my Diretta evaluation. For me, it’s busted in every aspect. And, after all this effort, I hope I’ll be allowed to express my own take on the whole experiment.
My Take
This exercise did nothing to change what I already knew about digital transports: when they work correctly and deliver unaltered bits in time, they can’t possibly make any difference in sound quality. There is no “buffer fallacy”; buffers work as intended and are your friend. Not only are they necessary to make every single digital audio solution work, they are the flywheel of digital transmissions.
It’s interesting that Diretta’s approach goes opposite to common sense. Making buffers larger actually reduces transmission frequency and the potential of the resulting EMI/RFI/XXI to affect sound. If transmissions happen seconds apart, they are already unlikely to influence quality. The ideal case would of course be to put an entire track or even album in memory and do zero transfers during playback. Instead, Diretta makes buffers as small as possible and transfers them continuously during playback, moving the system much closer to the edge in terms of stability. If you unplug the cable and the music stops [almost] immediately, you have a problem on your hands.
I’m aware this is not going to change many minds. Some people will continue to “evolve” Diretta, others will continue to push it as a “groundbreaking” technology, and others will continue to hear the angels sing when listening to it. But for the ones who are willing to listen, I’ll say this: if you find yourself tweaking the digital side of your system to squeeze more quality out of a bit-perfect playback, what you’re trying to do is fix the hole in your roof by controlling the weather to make it rain less. If you think you have a hole in your roof, just plug it: get a DAC that is immune to input noise. It won’t break the bank. When you let computers, networks and DACs do their intended jobs, the only job left for you is to enjoy the music. Happy holidays!
Let me know if you have any comments or measuring suggestions.